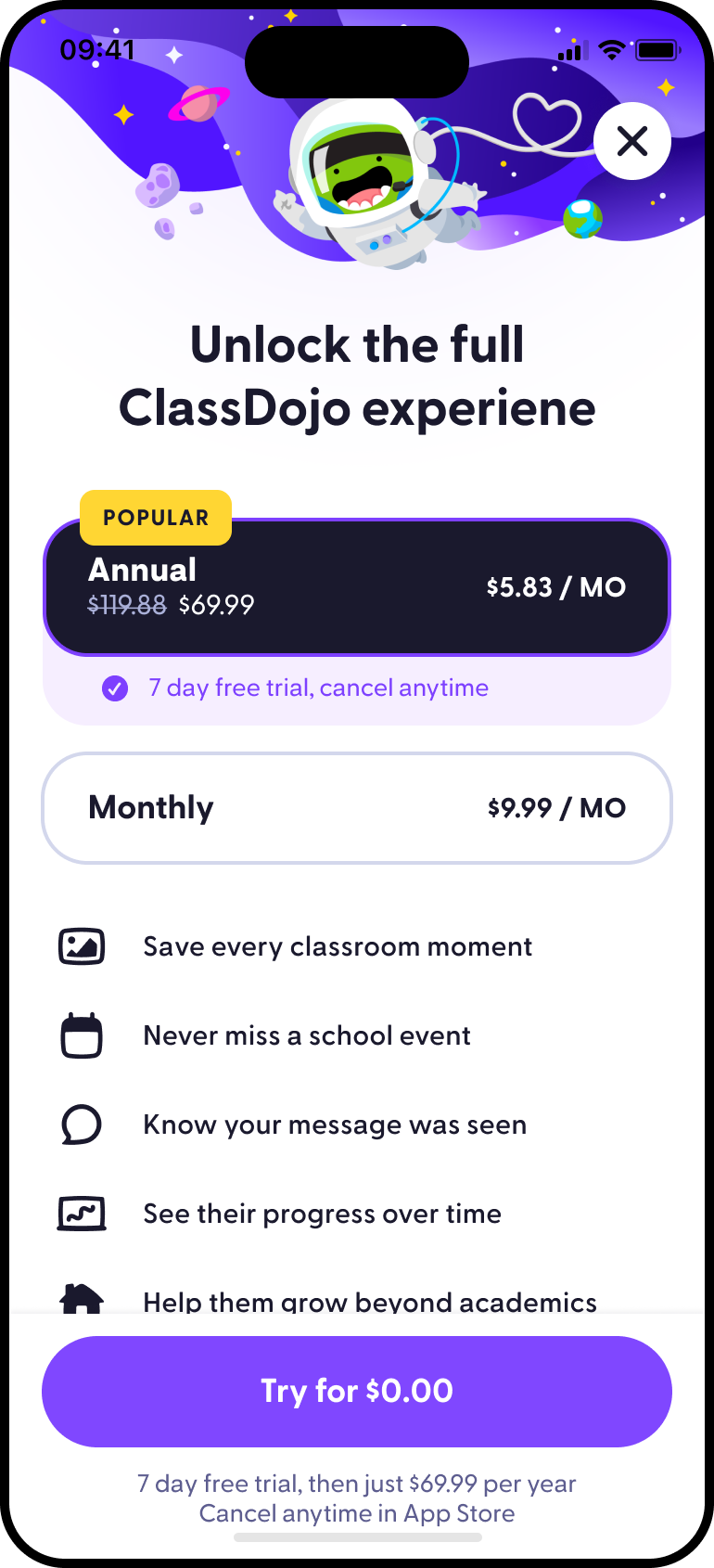
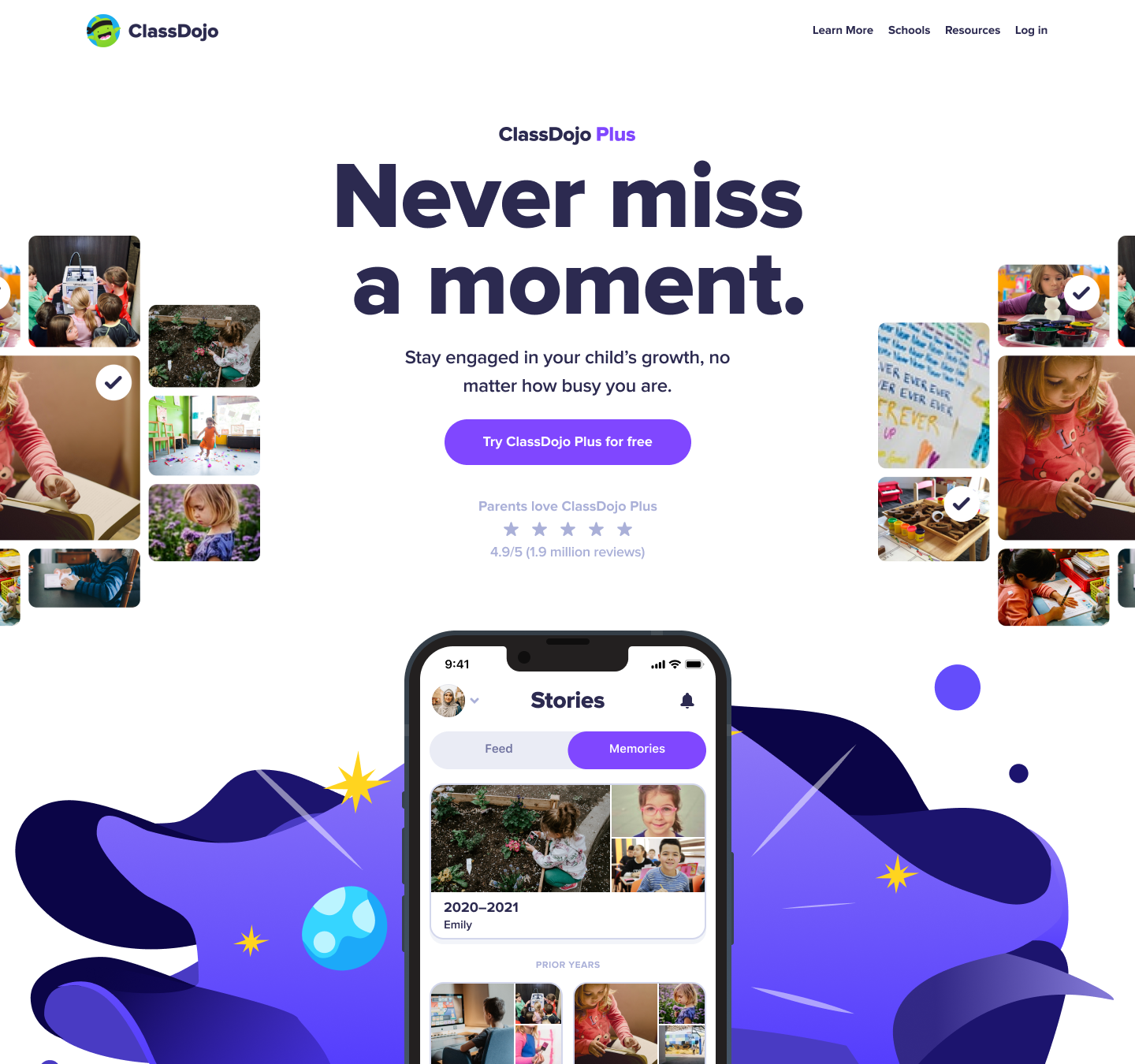
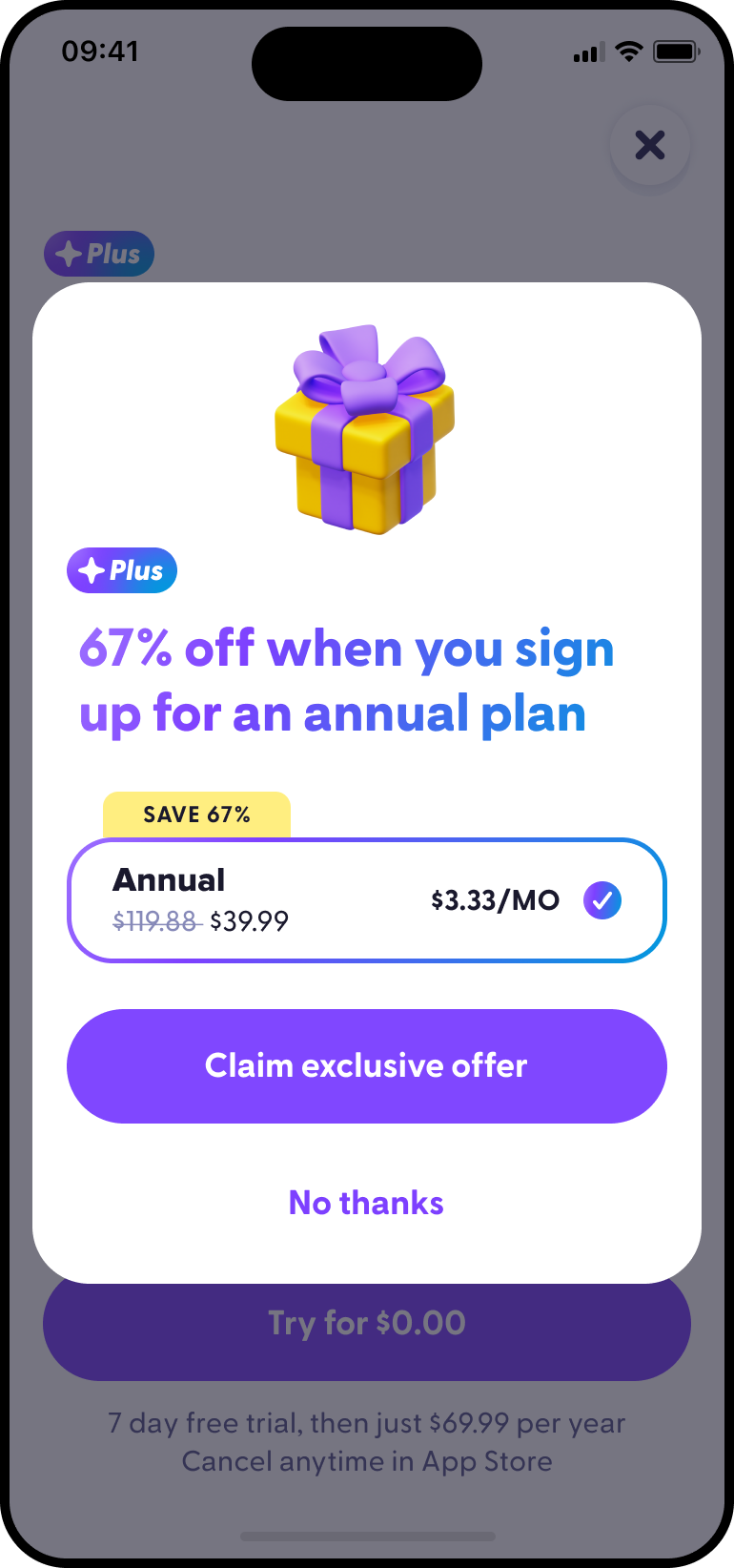
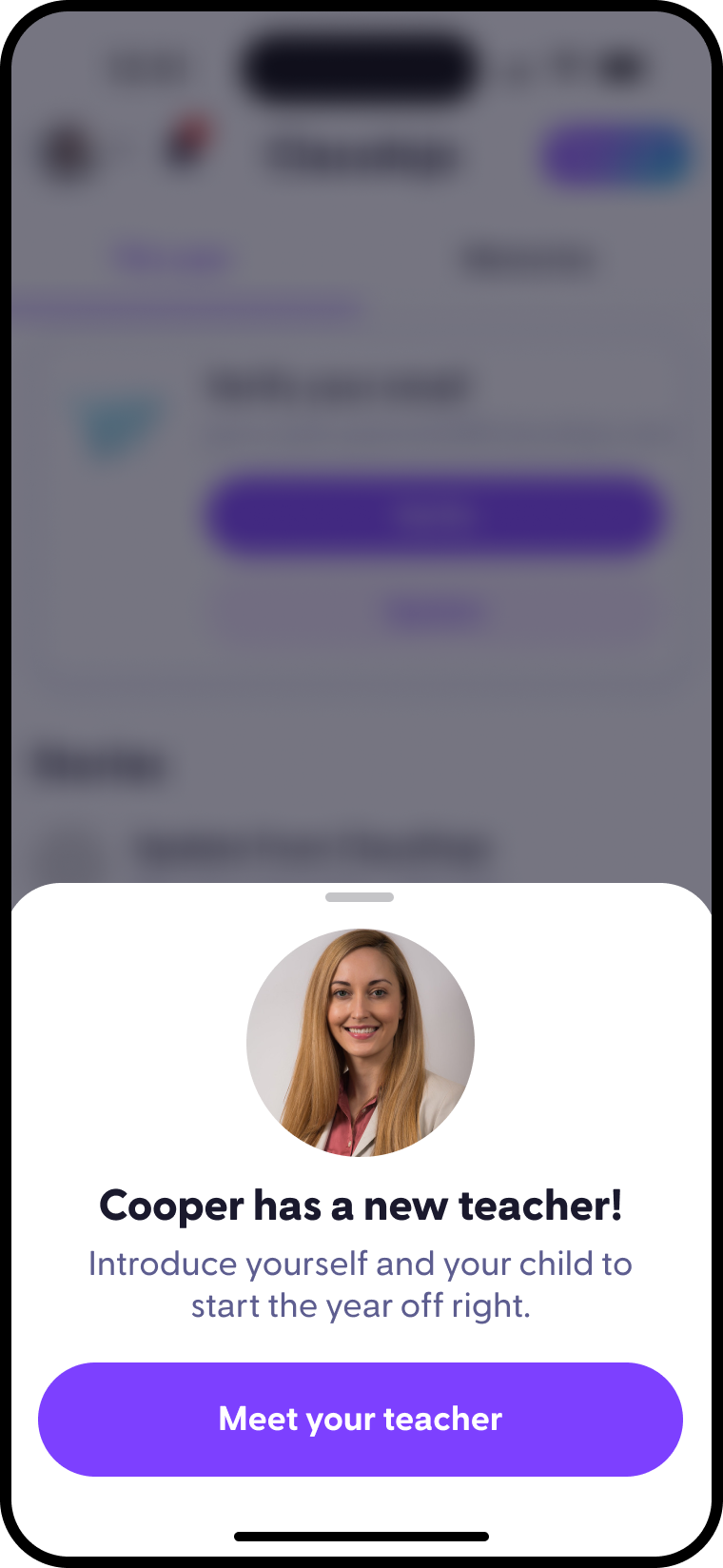
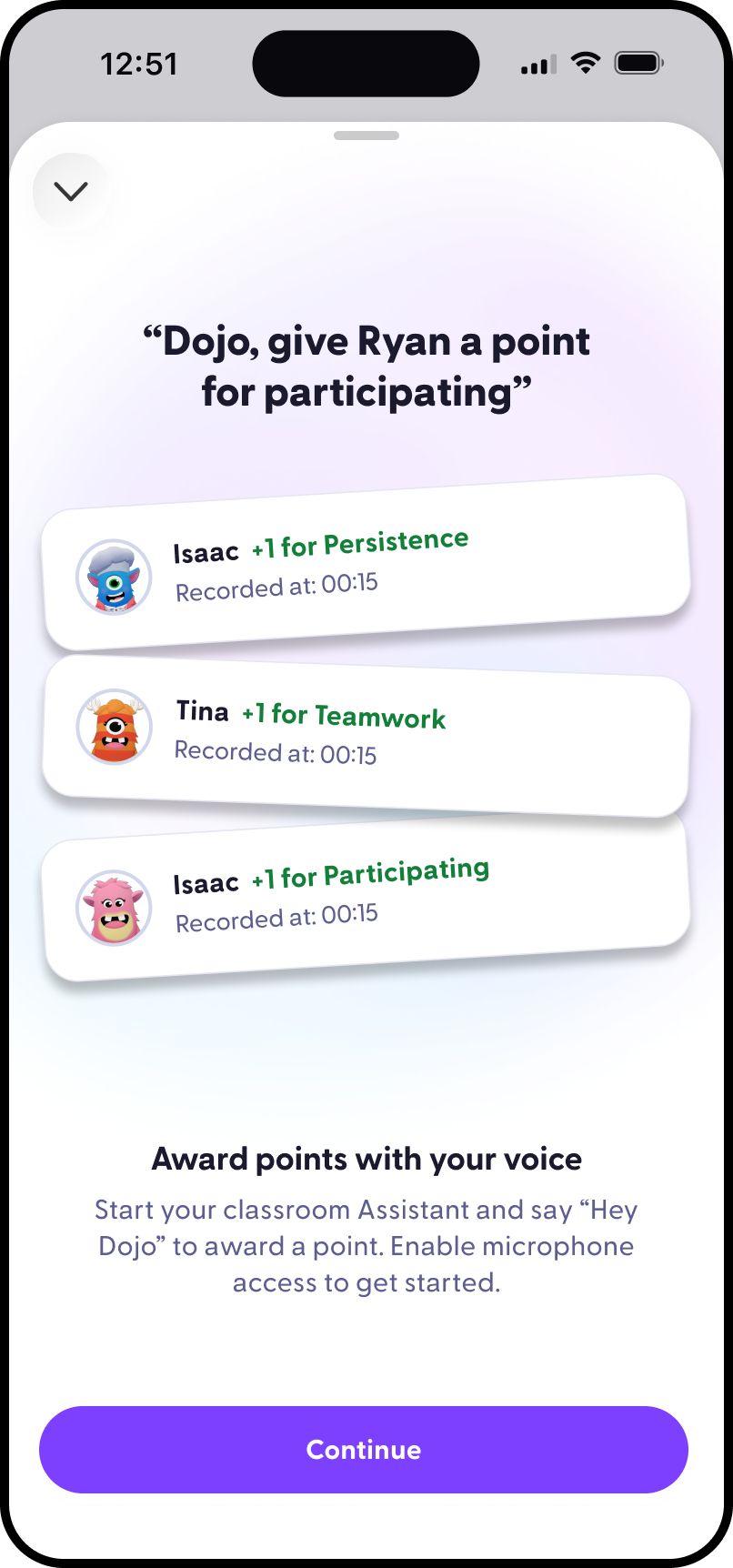
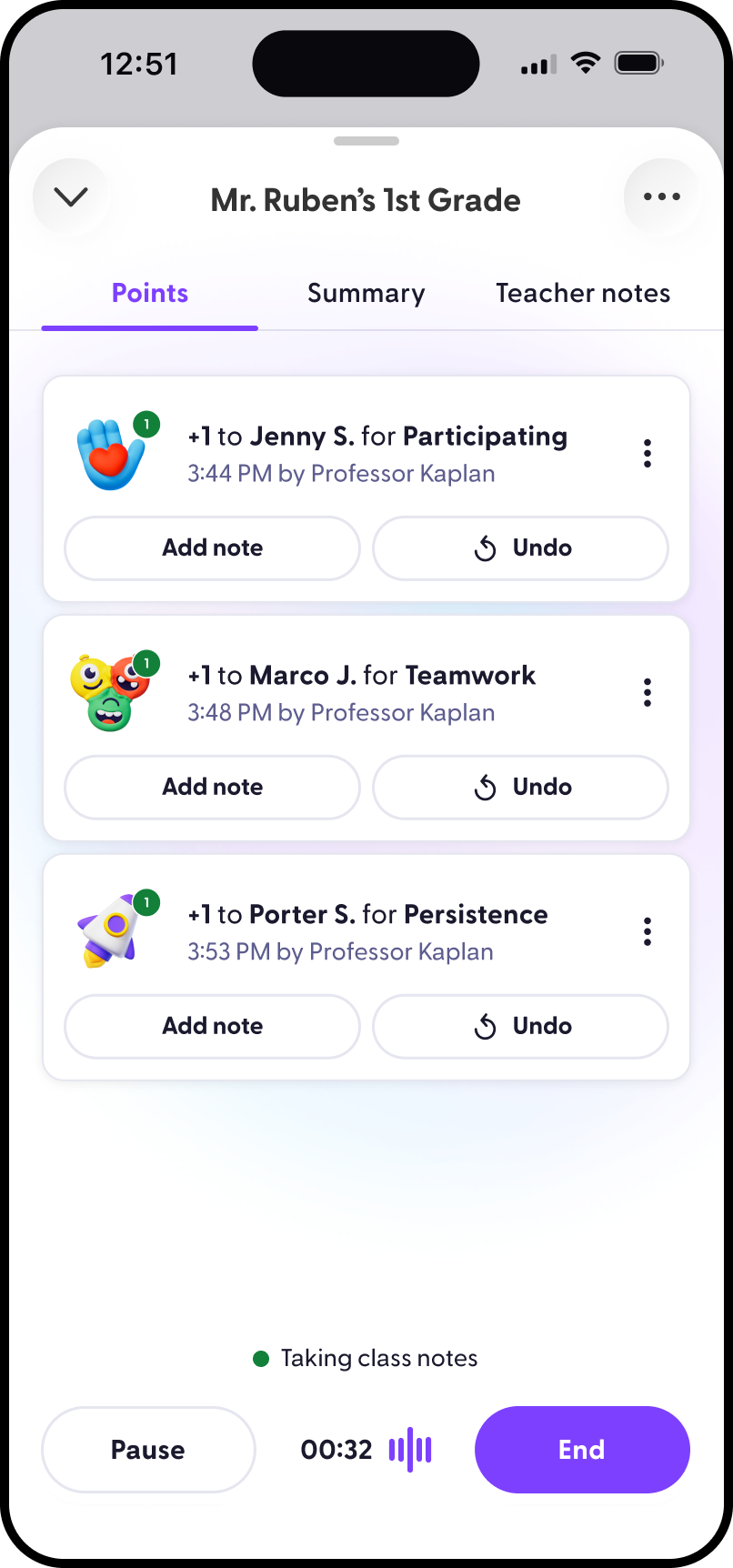
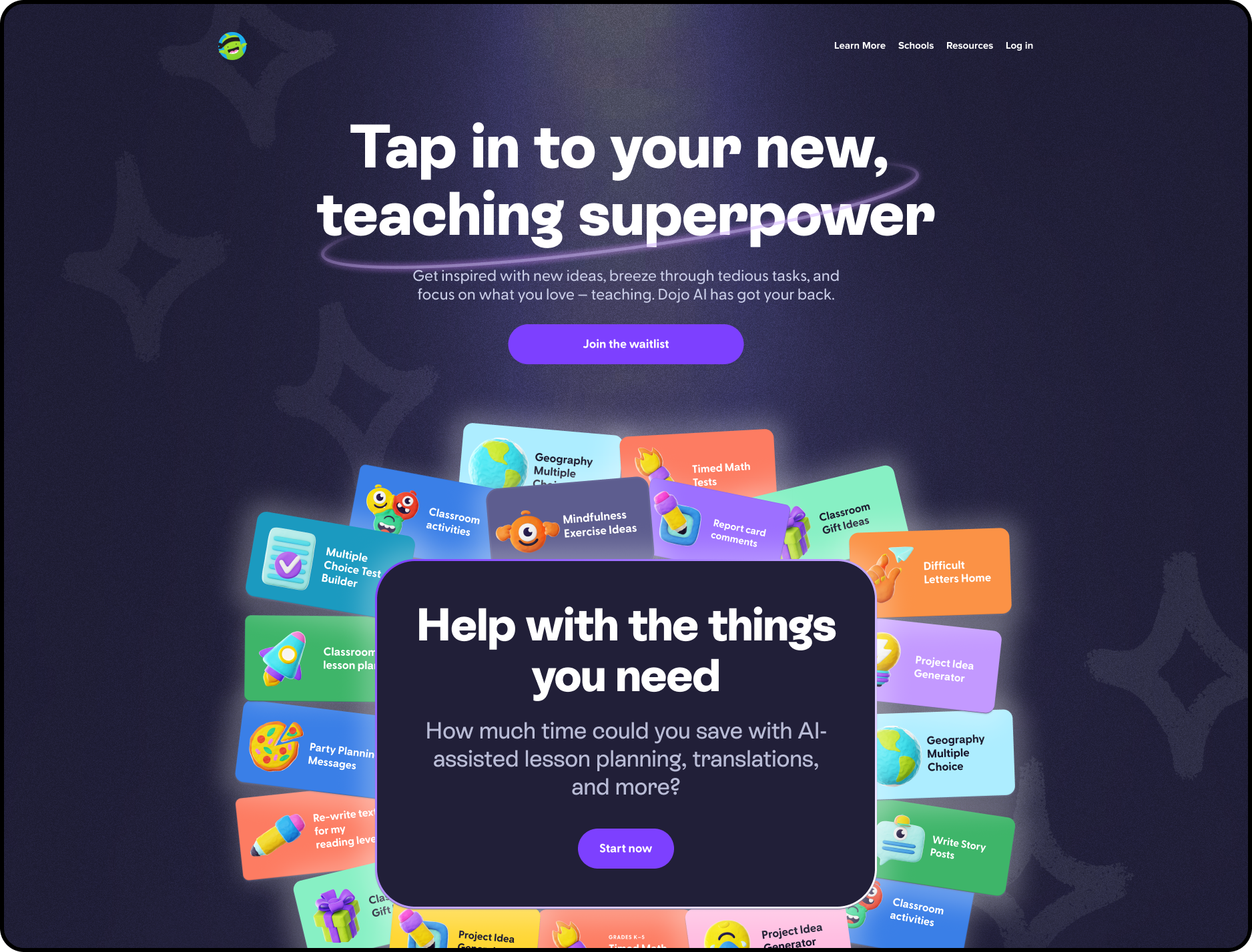
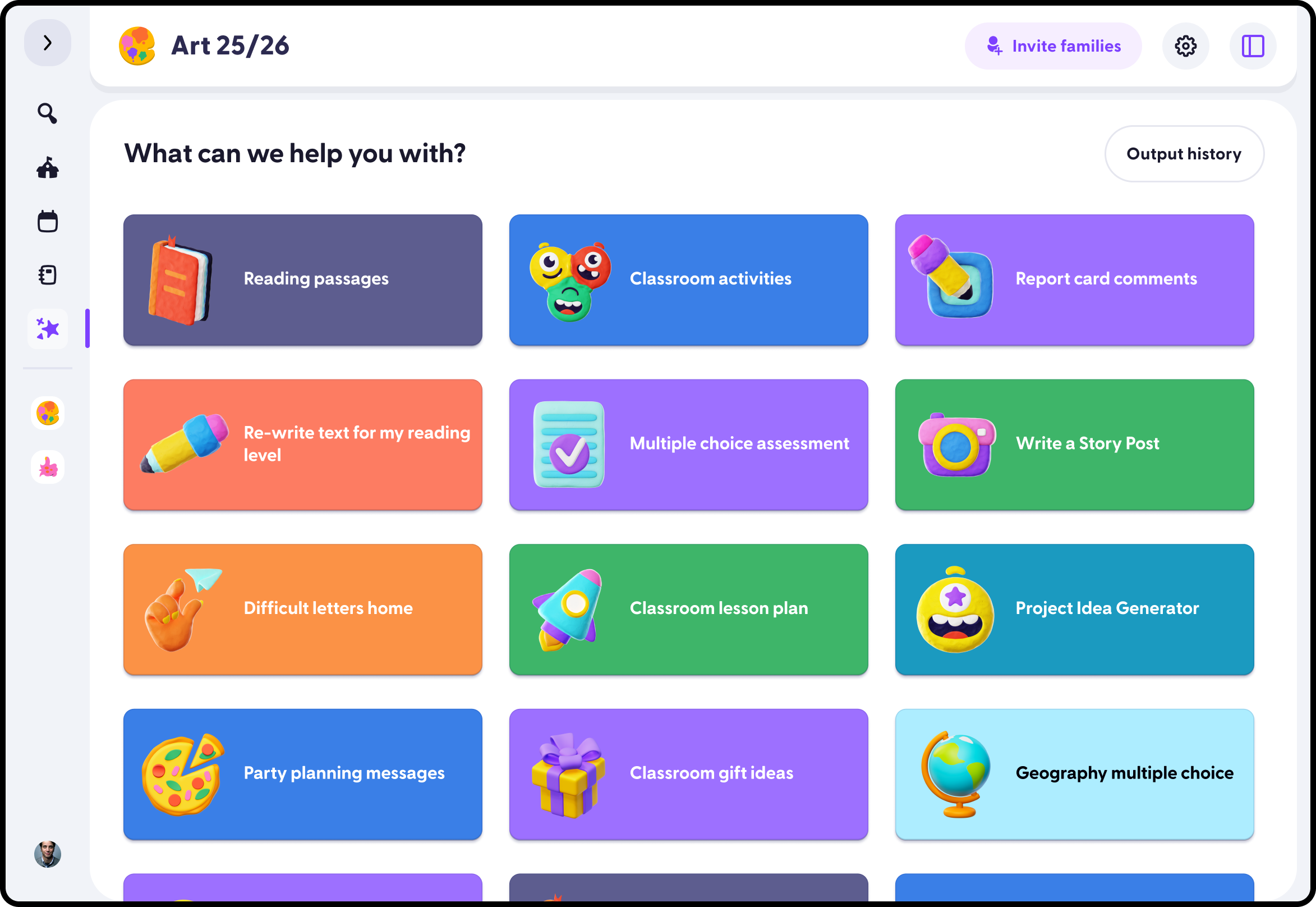
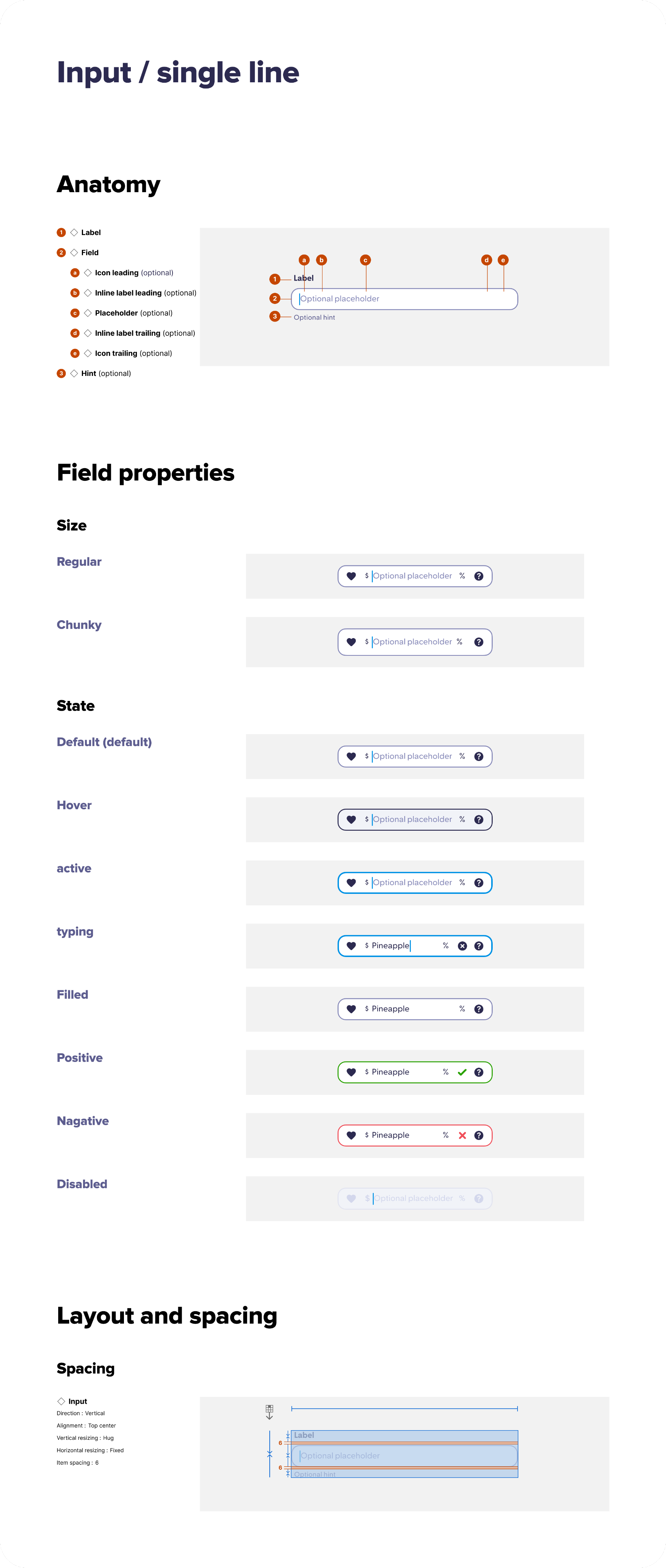
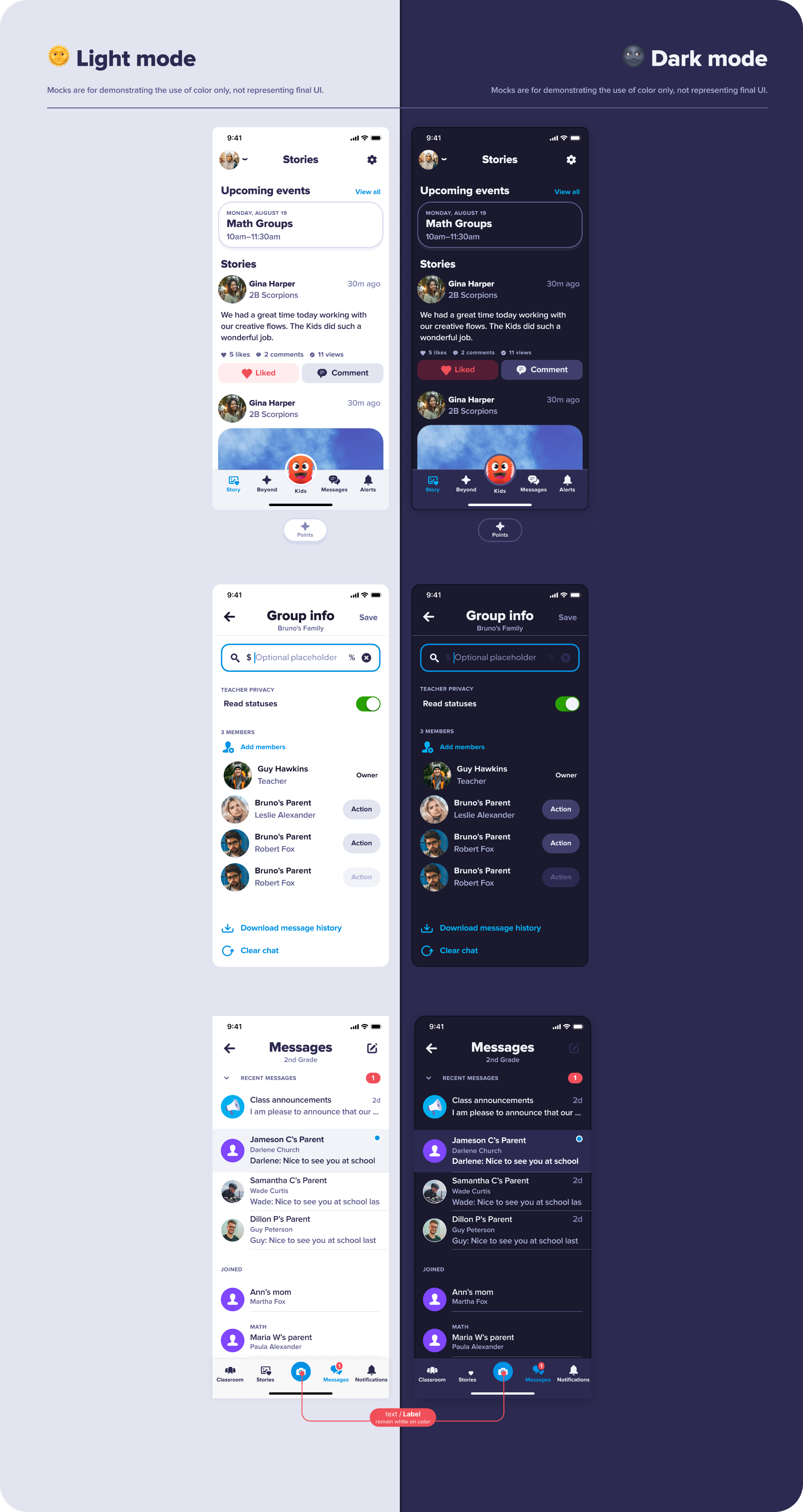
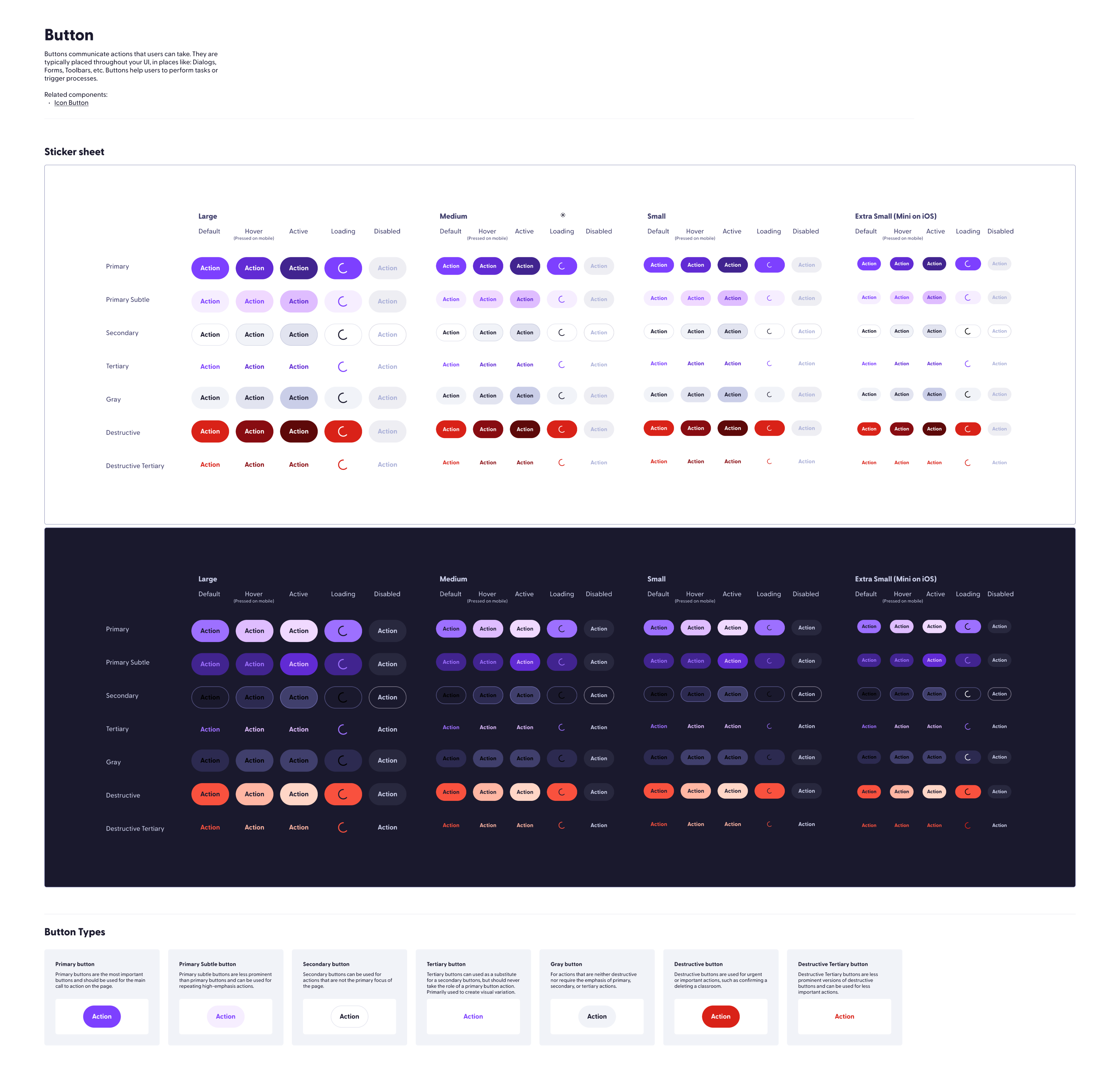
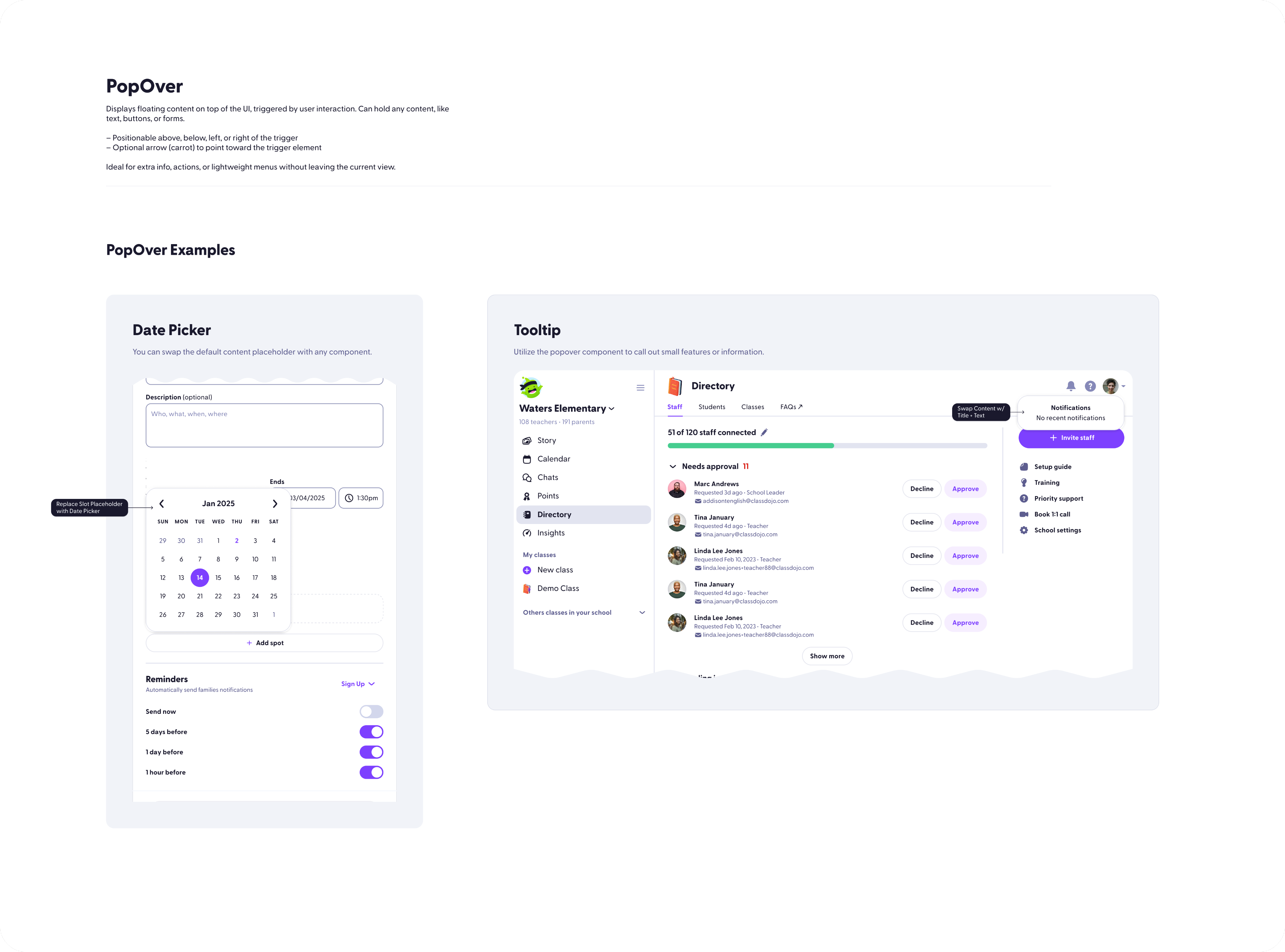
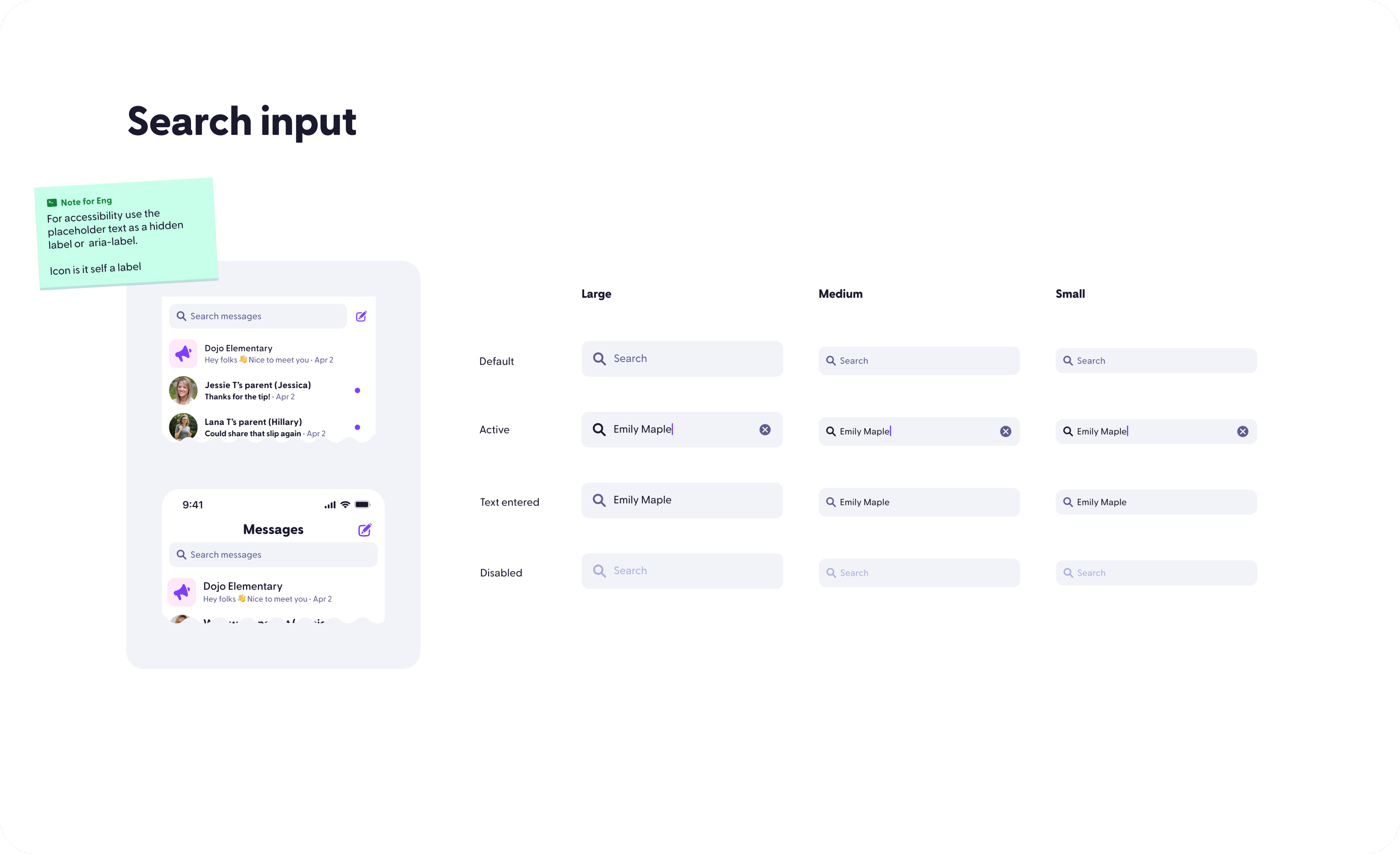
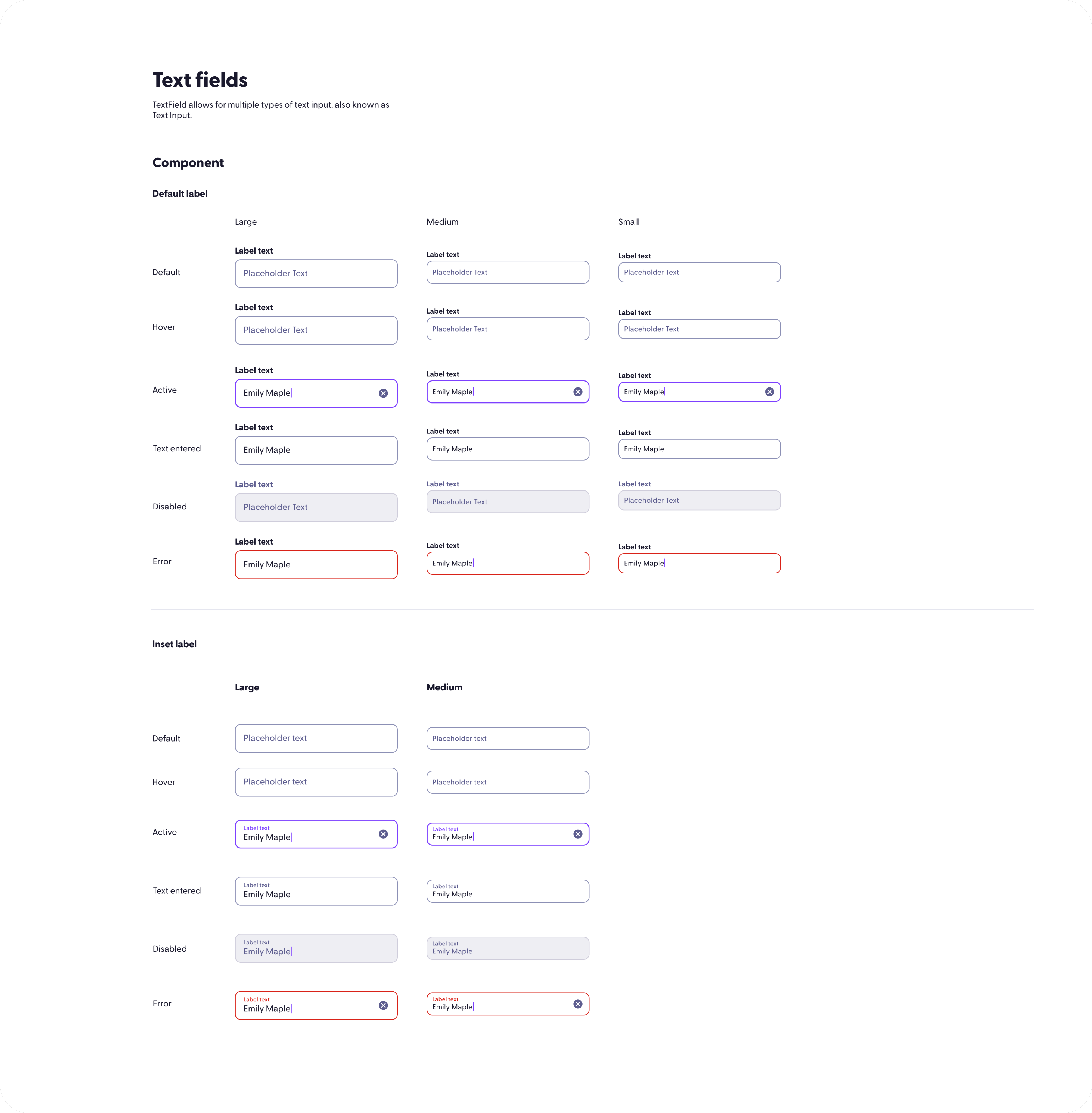
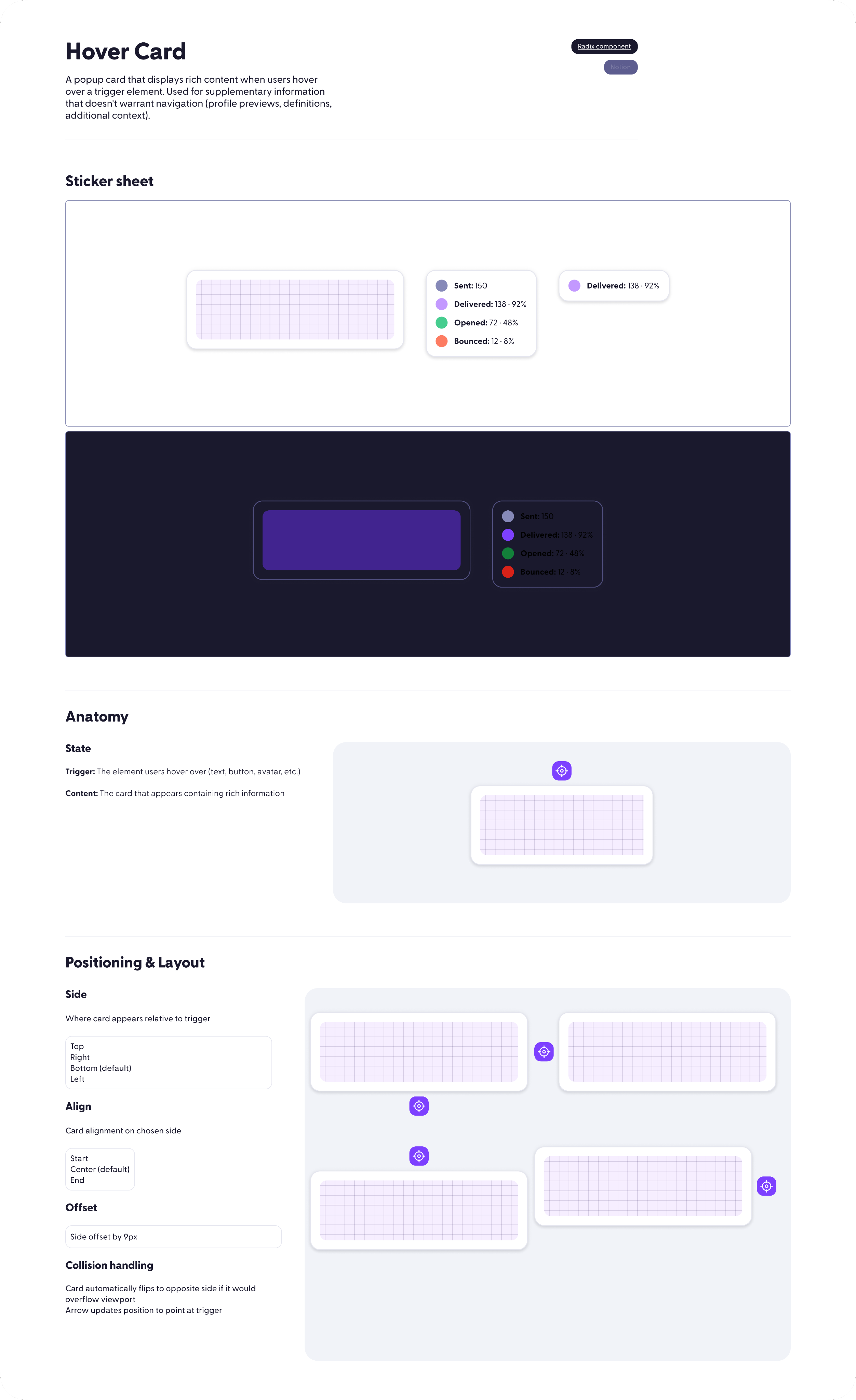
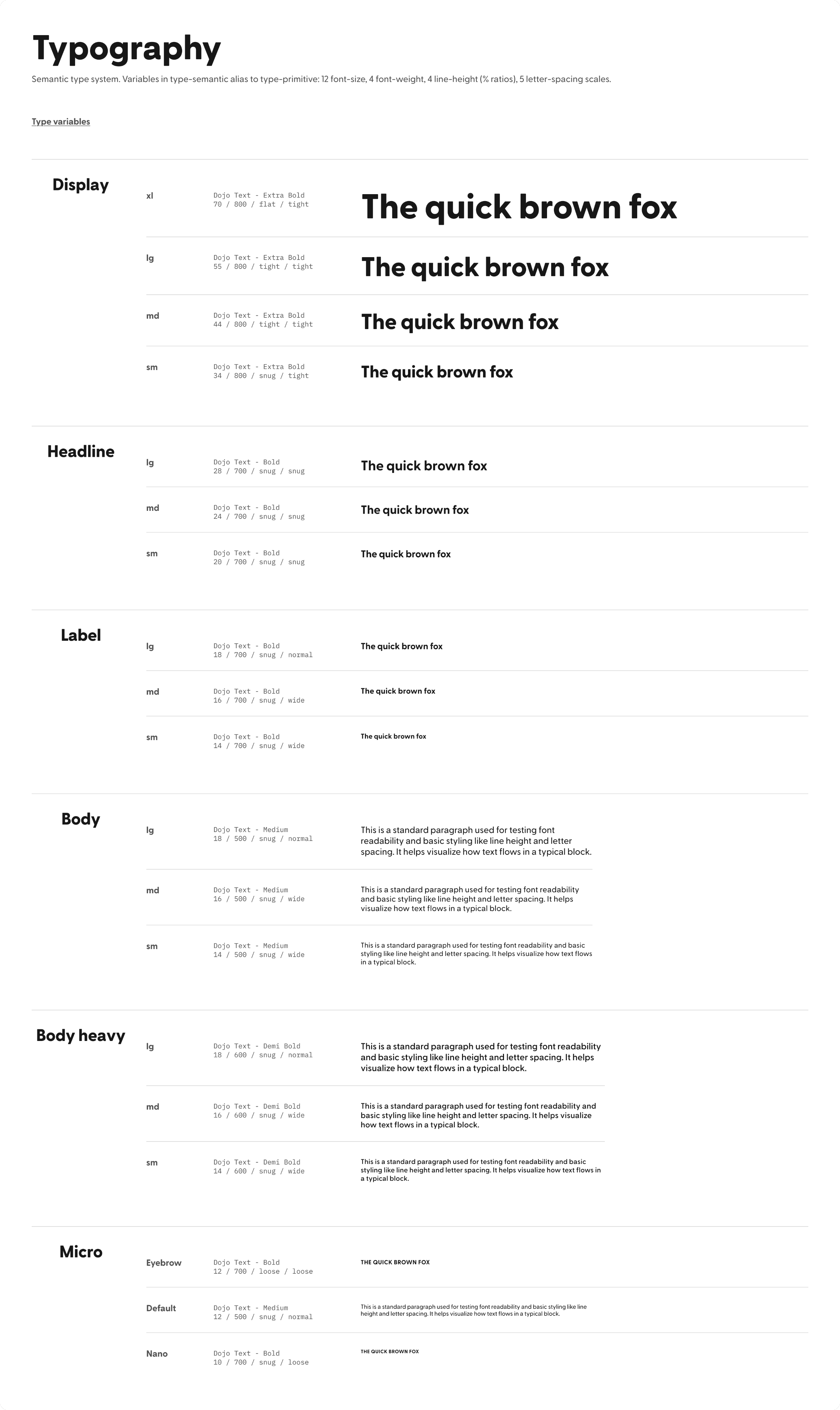
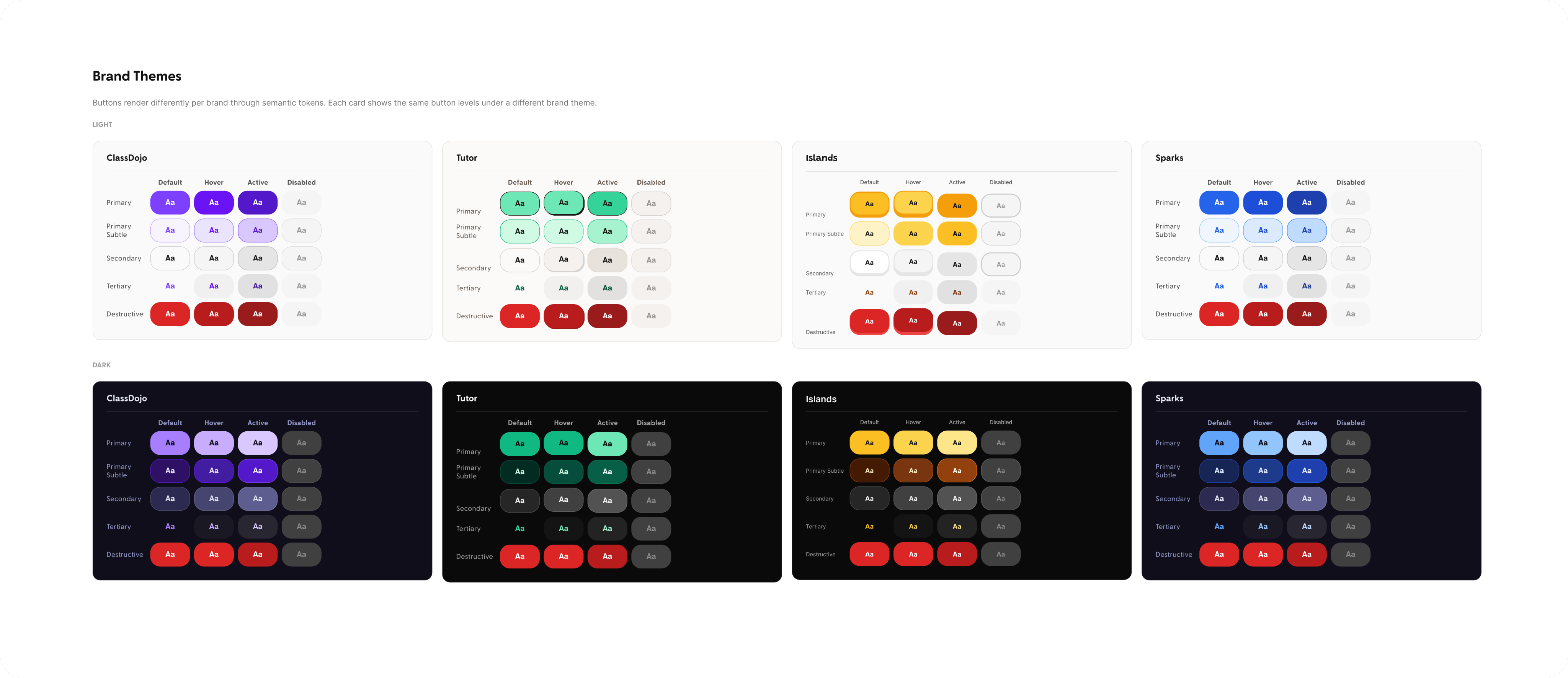
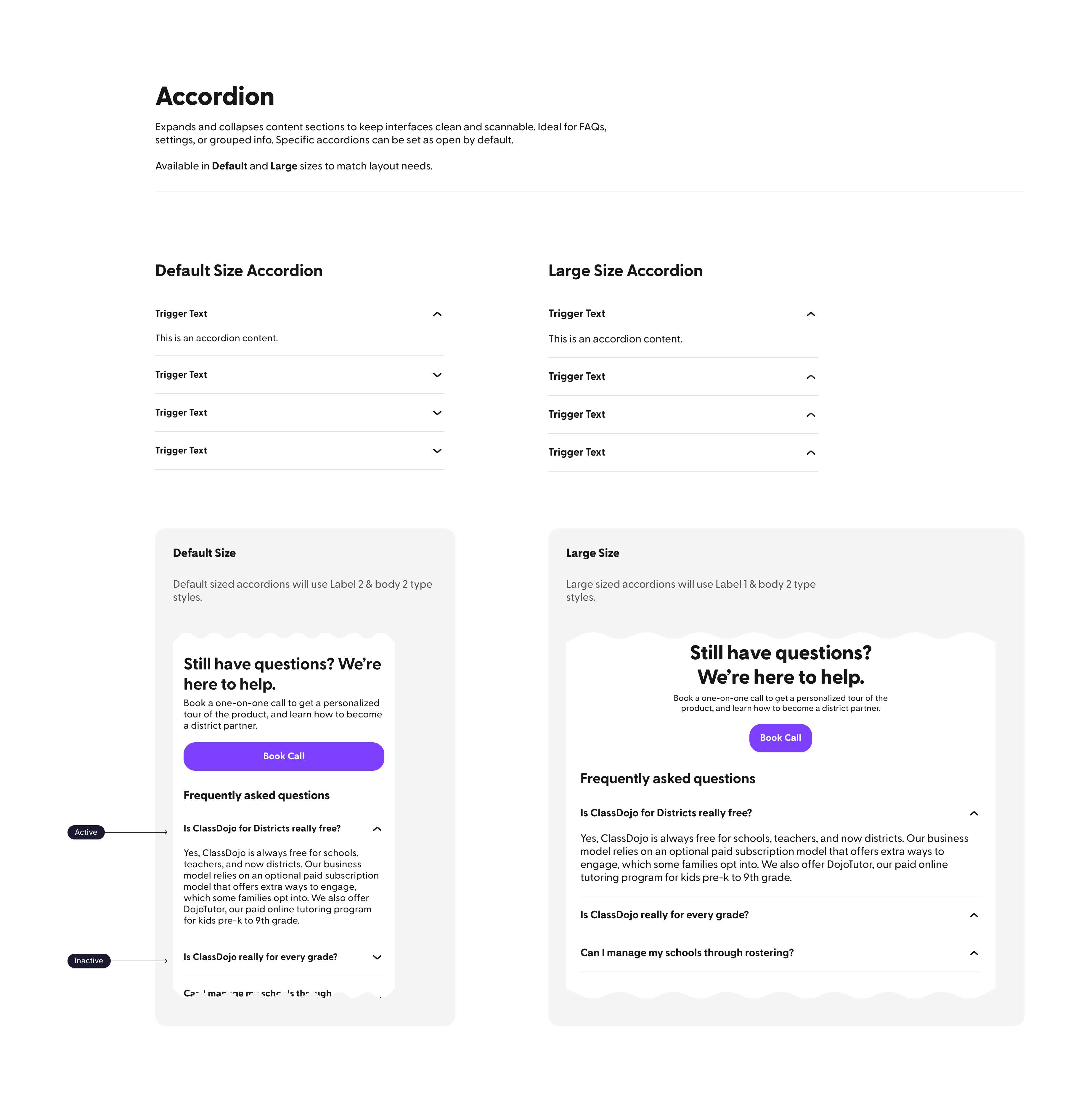
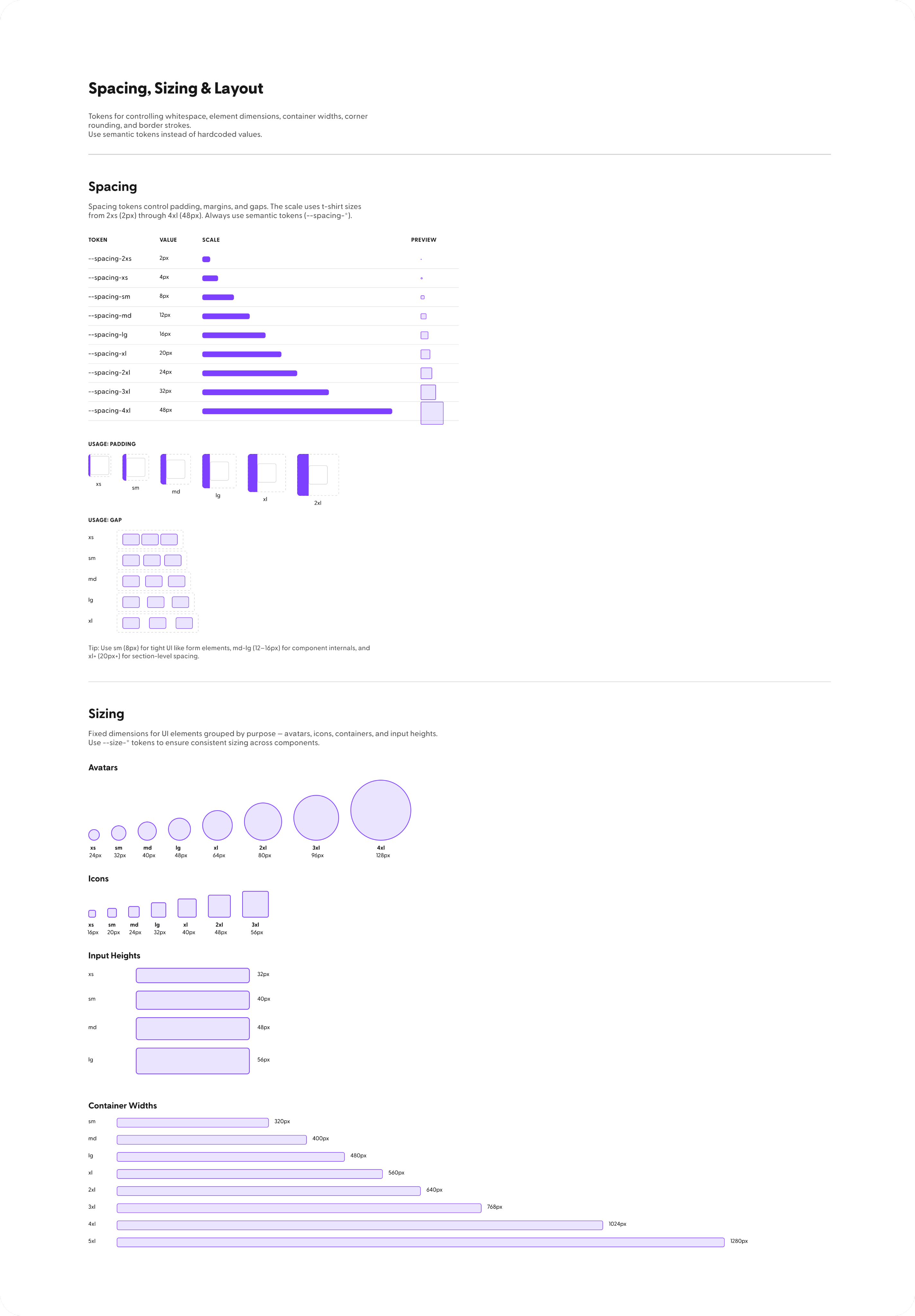
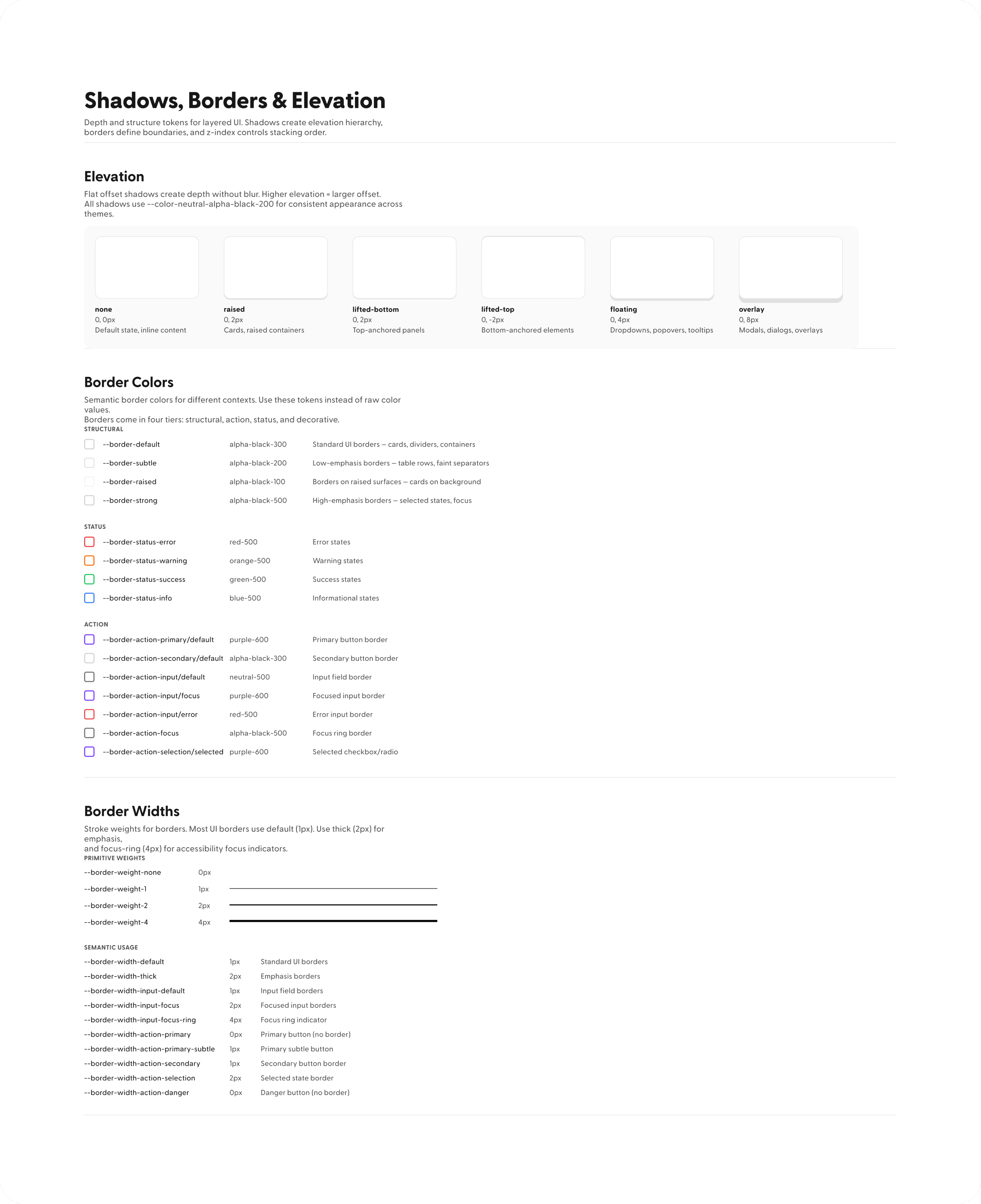
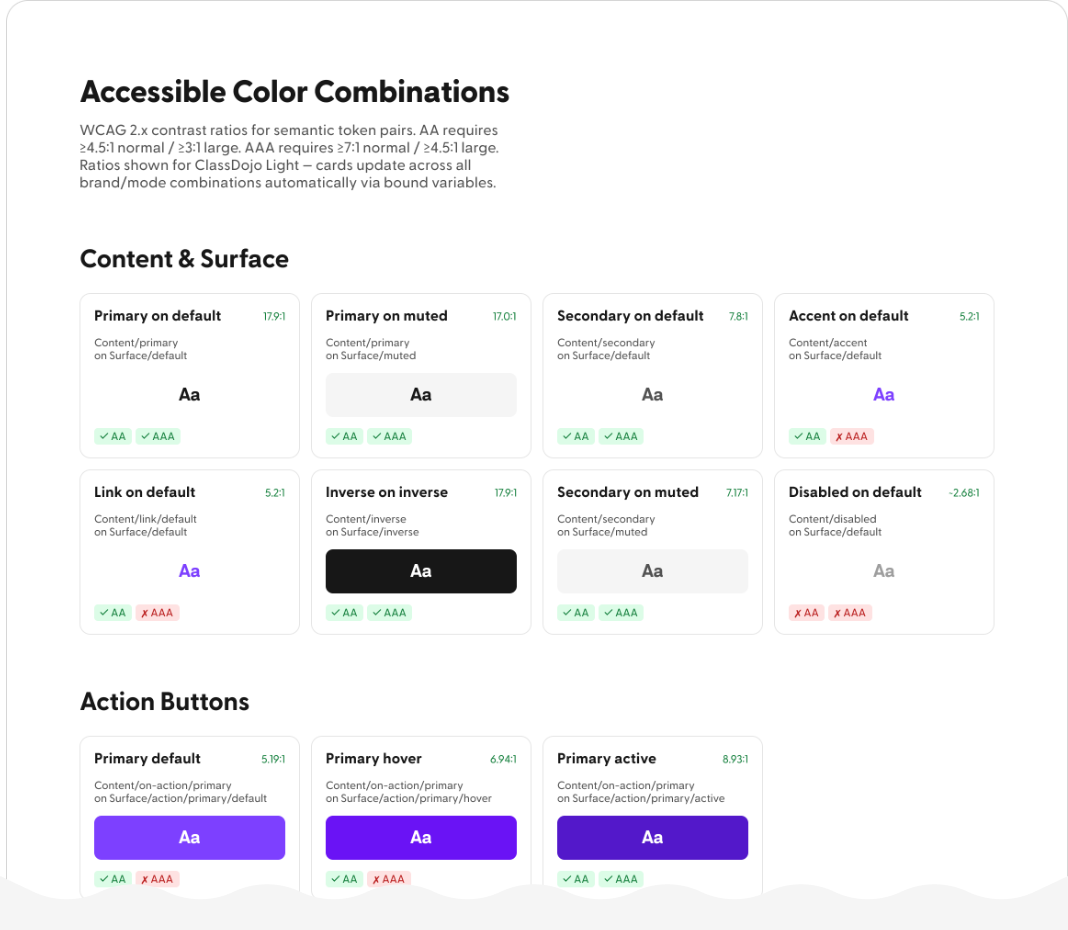
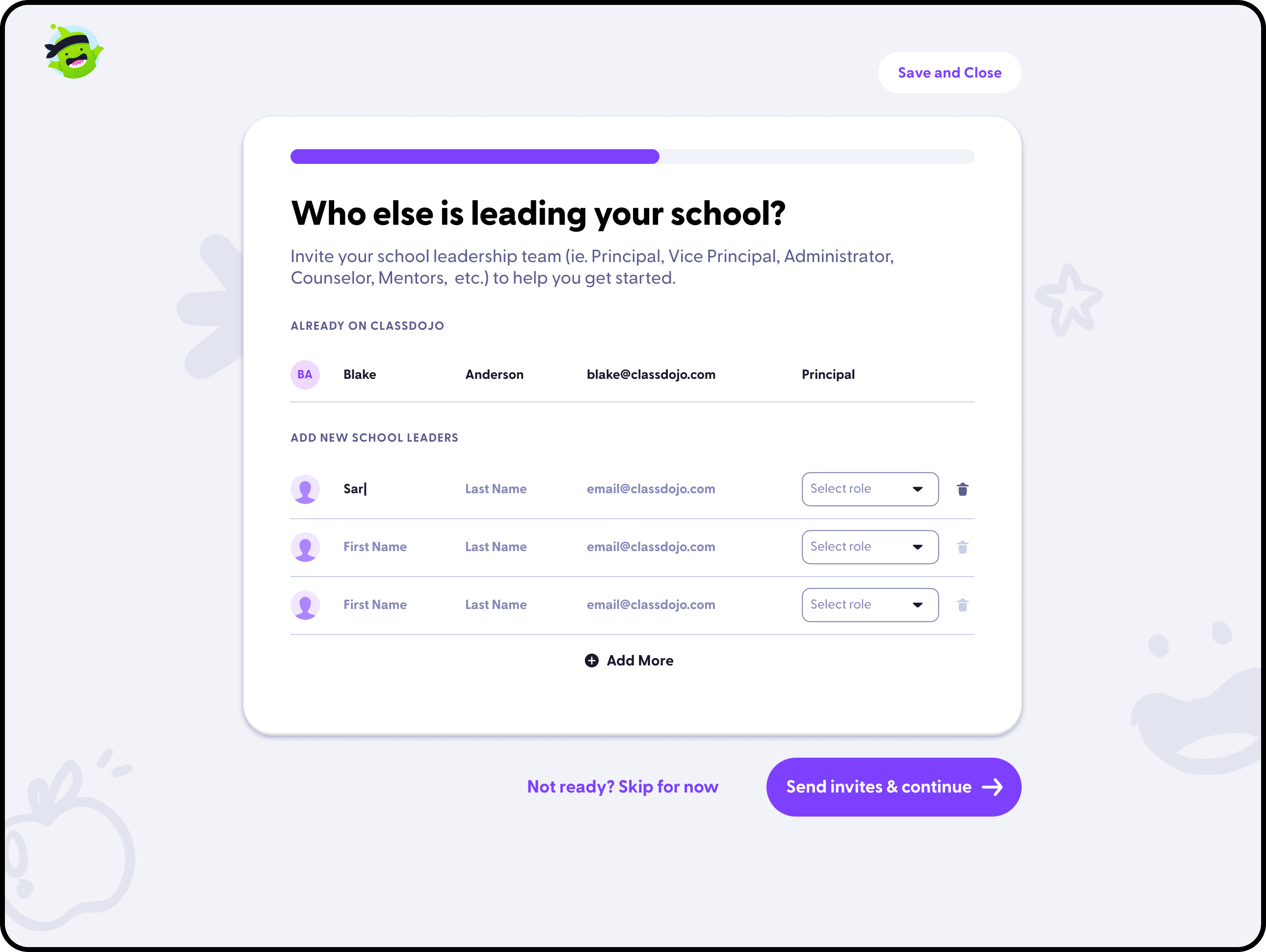
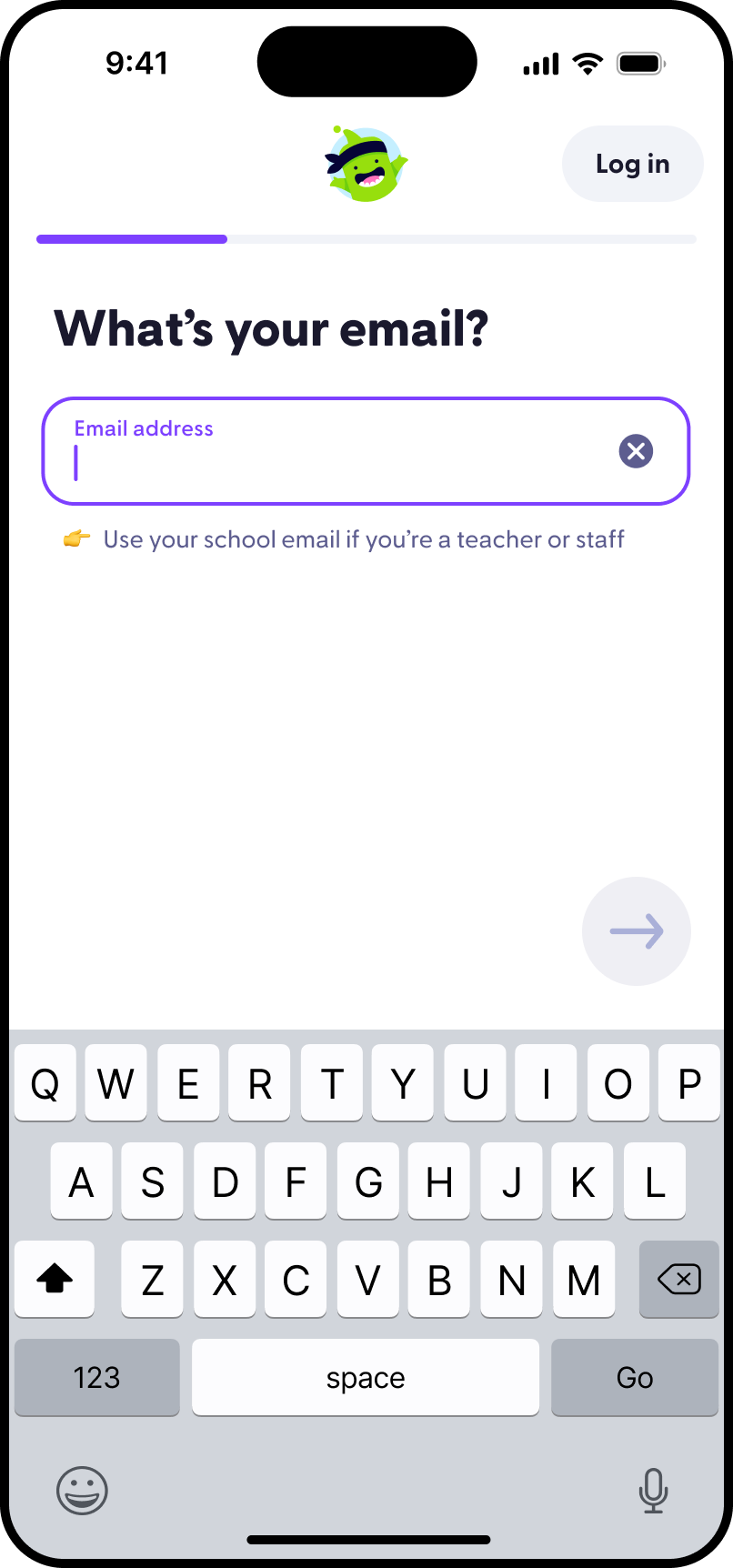
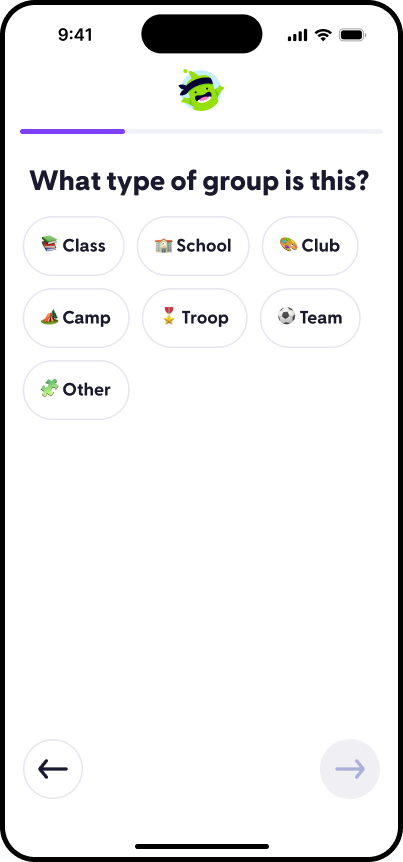
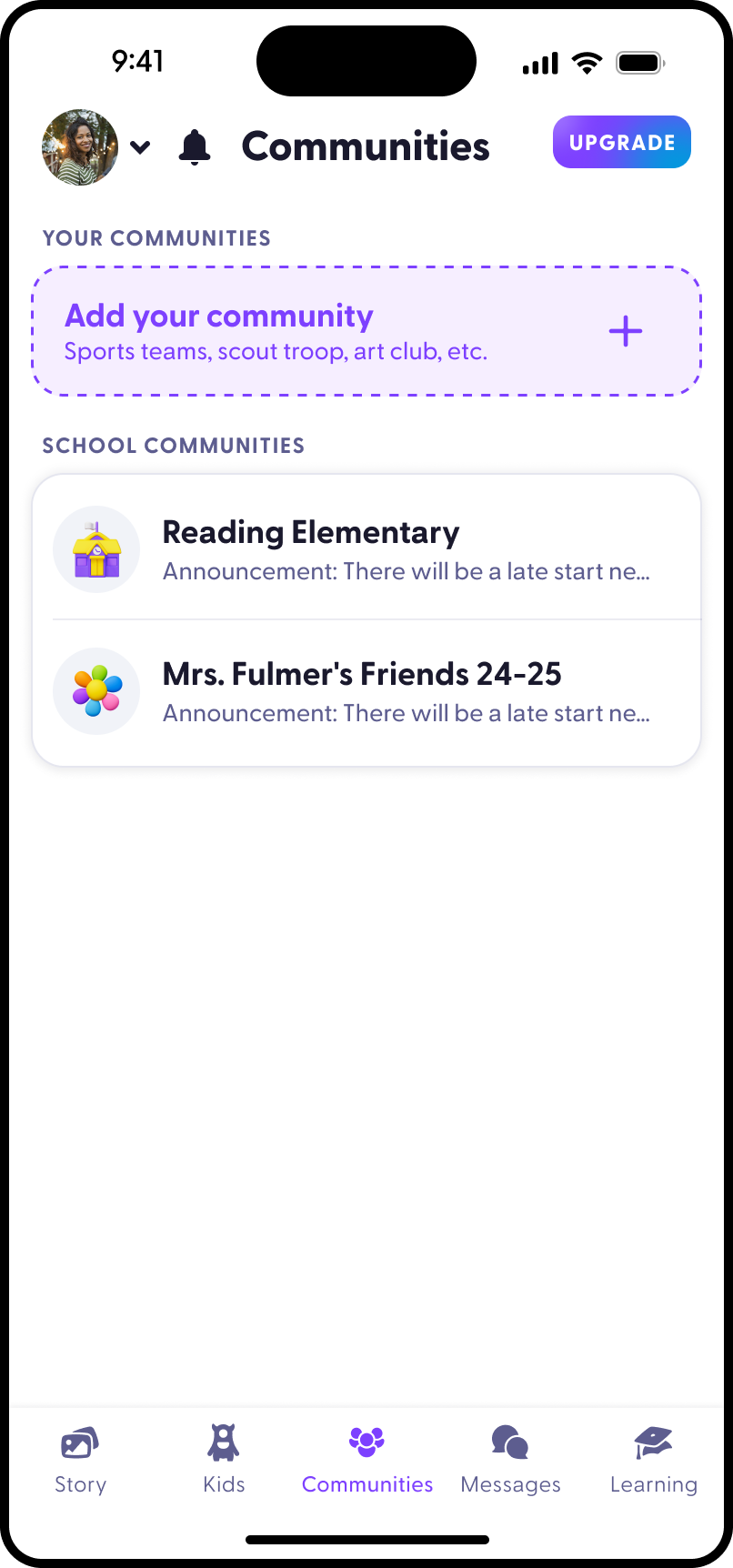
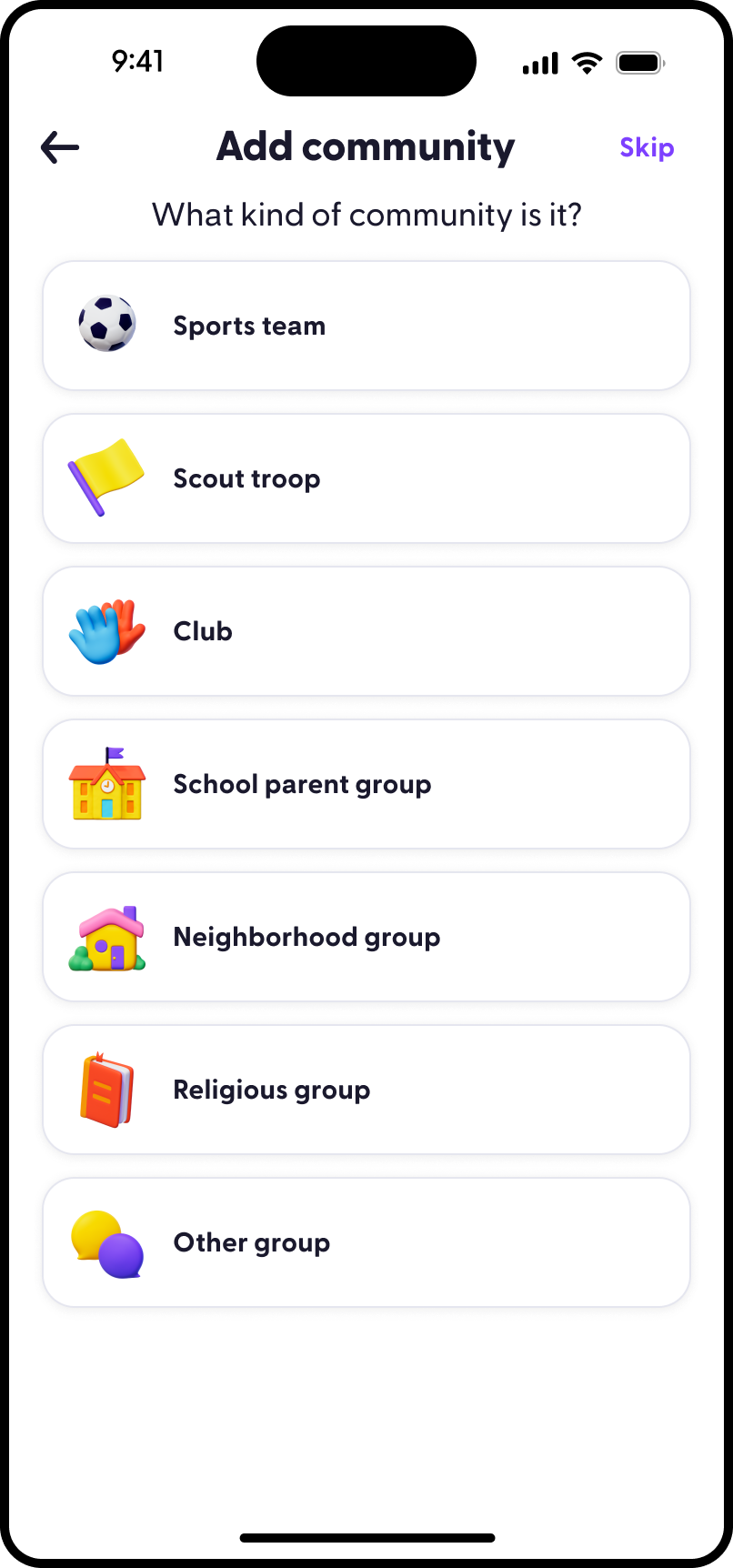
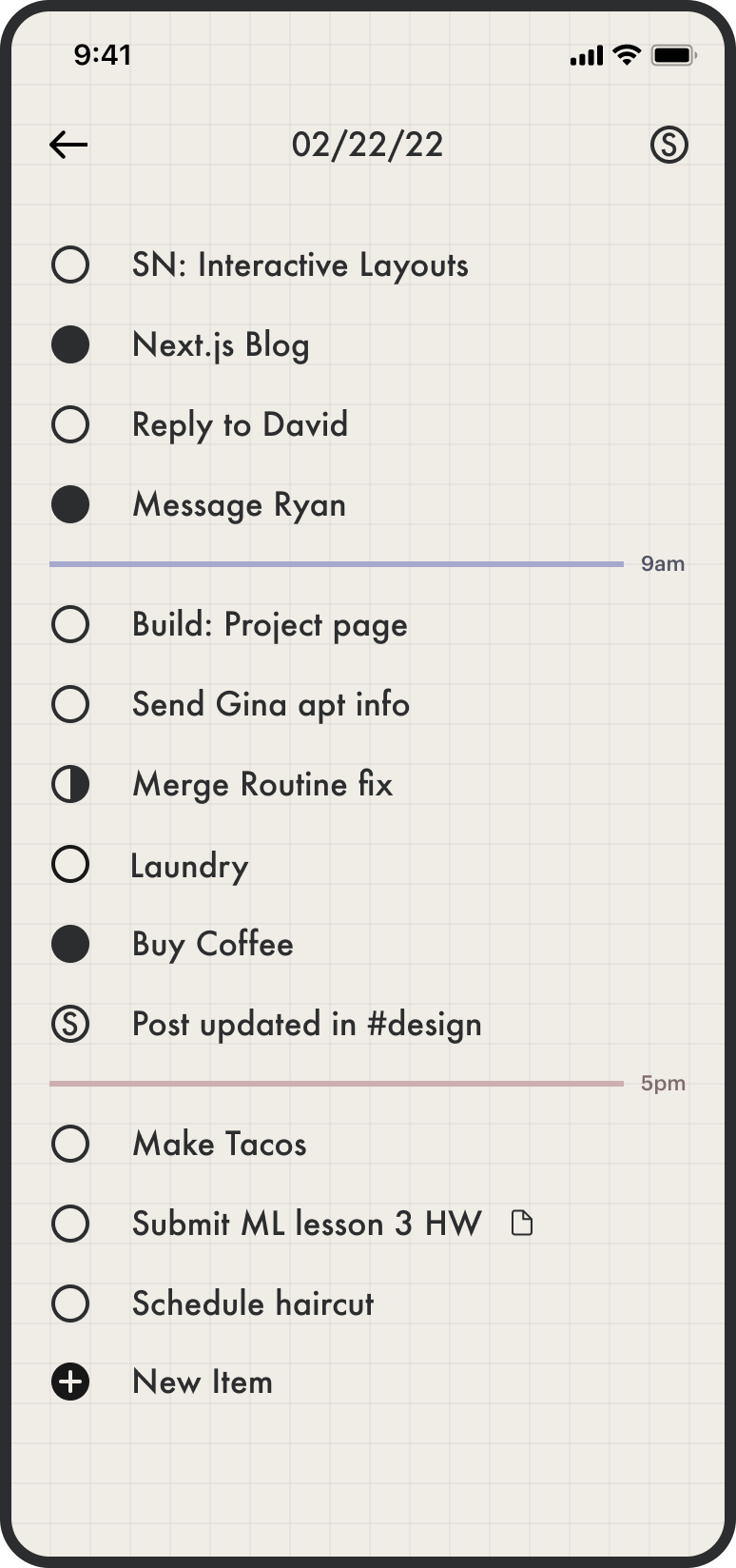
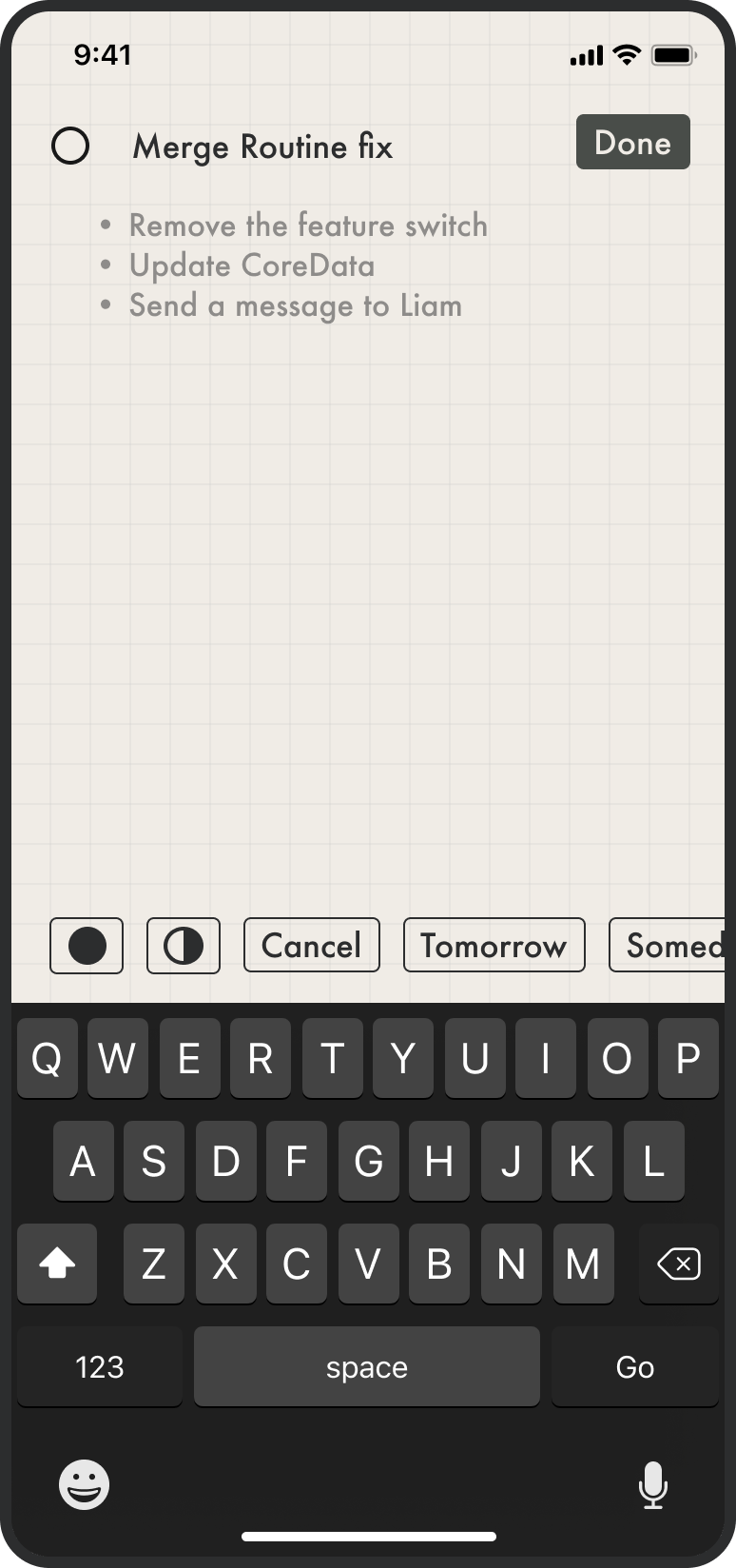
Who I am
I’m Blake Anderson, a product designer and design engineer who likes working close
to the outcome. I’m happiest in the messy middle of product, growth, brand, and
implementation: shaping the strategy, designing the system, and building enough of it
to learn quickly.
How I work
I like tight loops between thinking, making, shipping, and measuring. I’ll sketch the
product shape, sweat the interface details, write production code when it helps, and
use data to sharpen the next decision instead of treating design as a handoff.
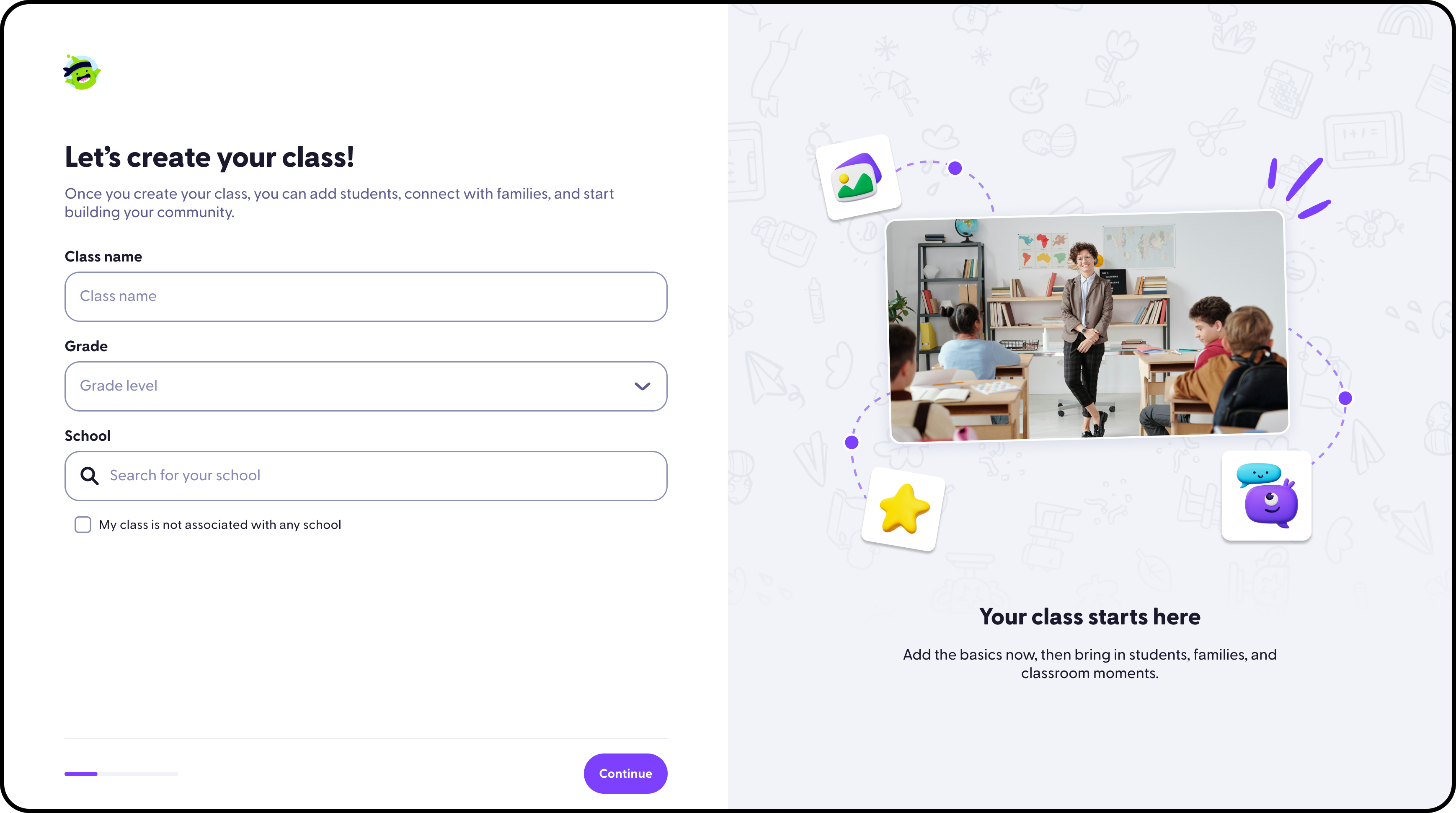
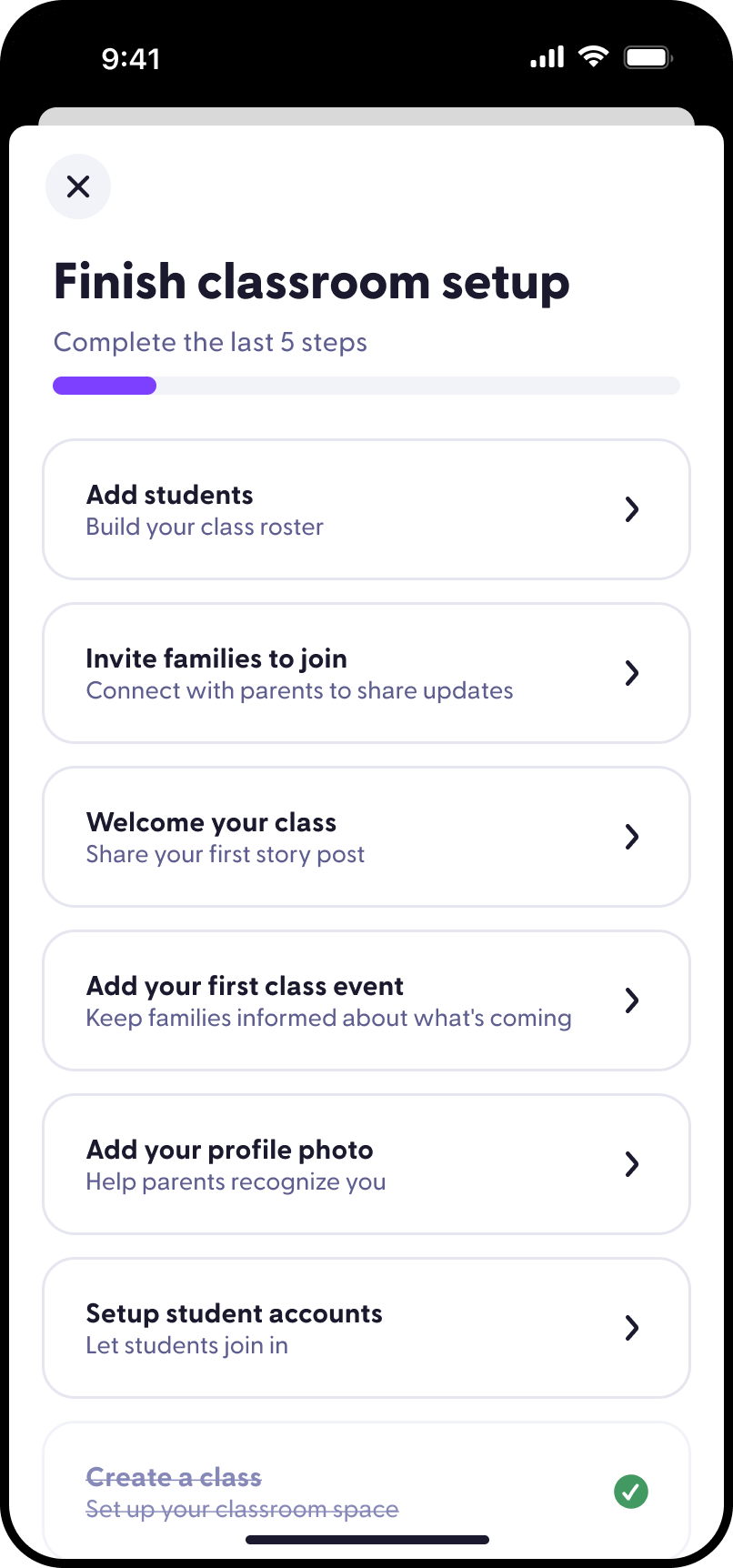
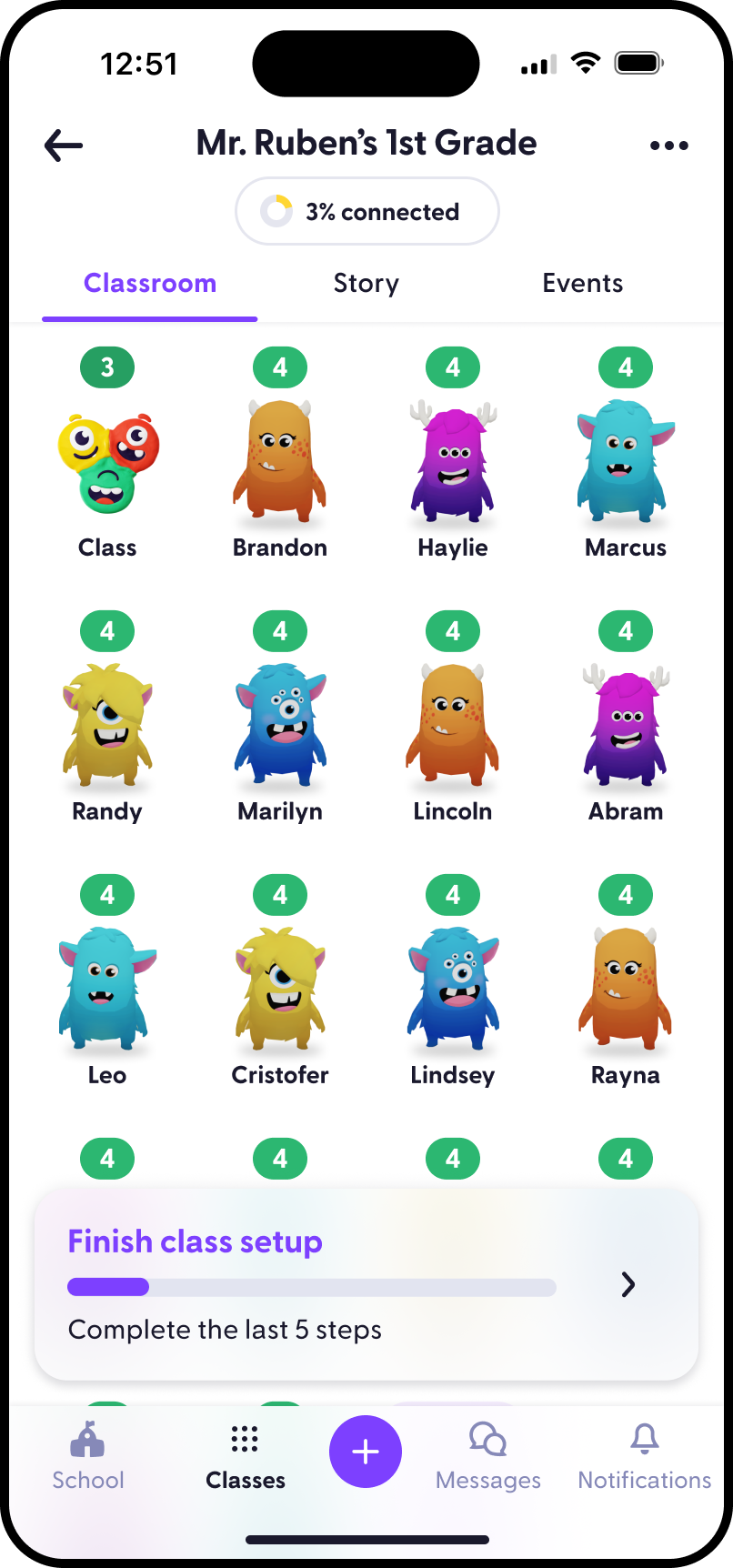
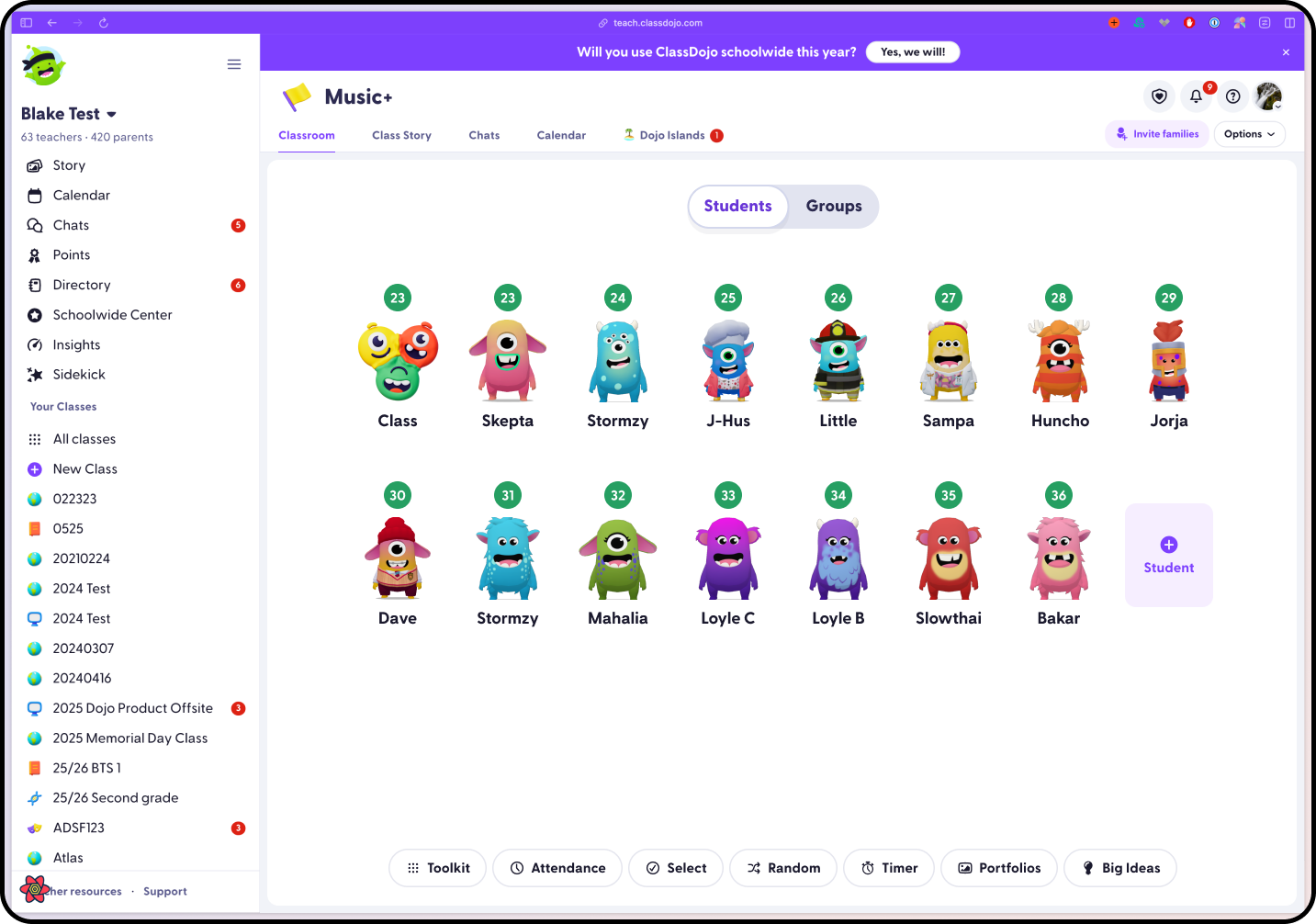
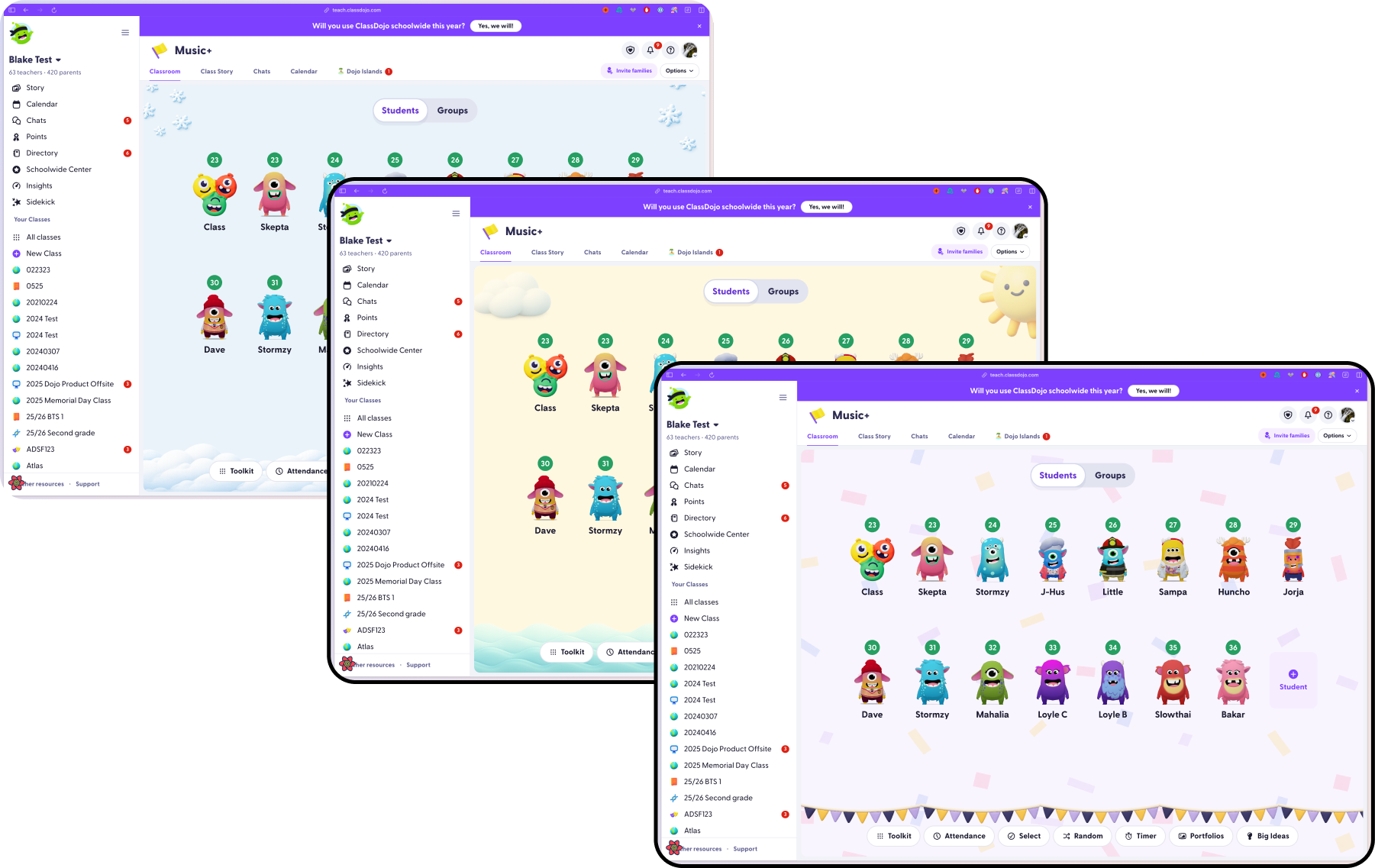
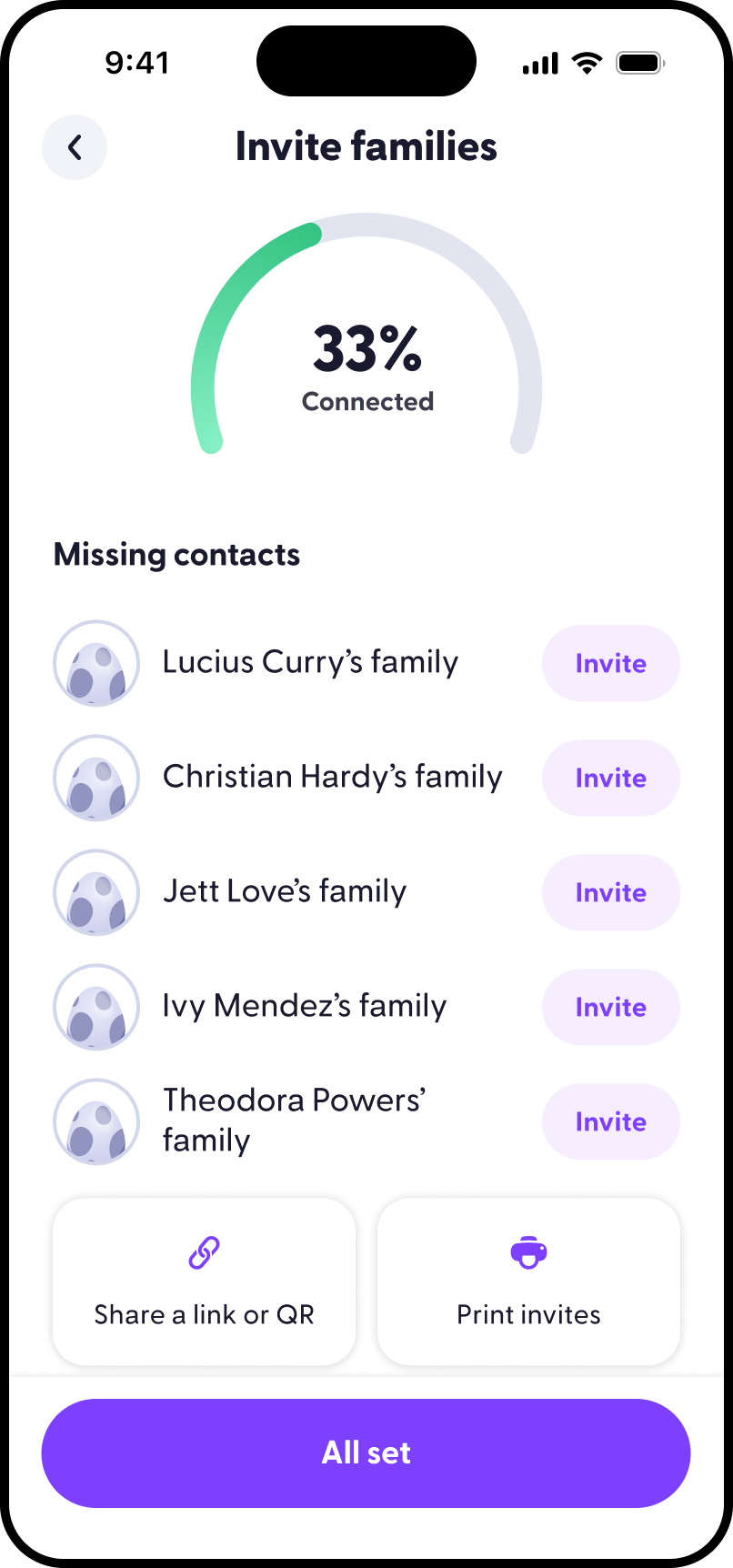
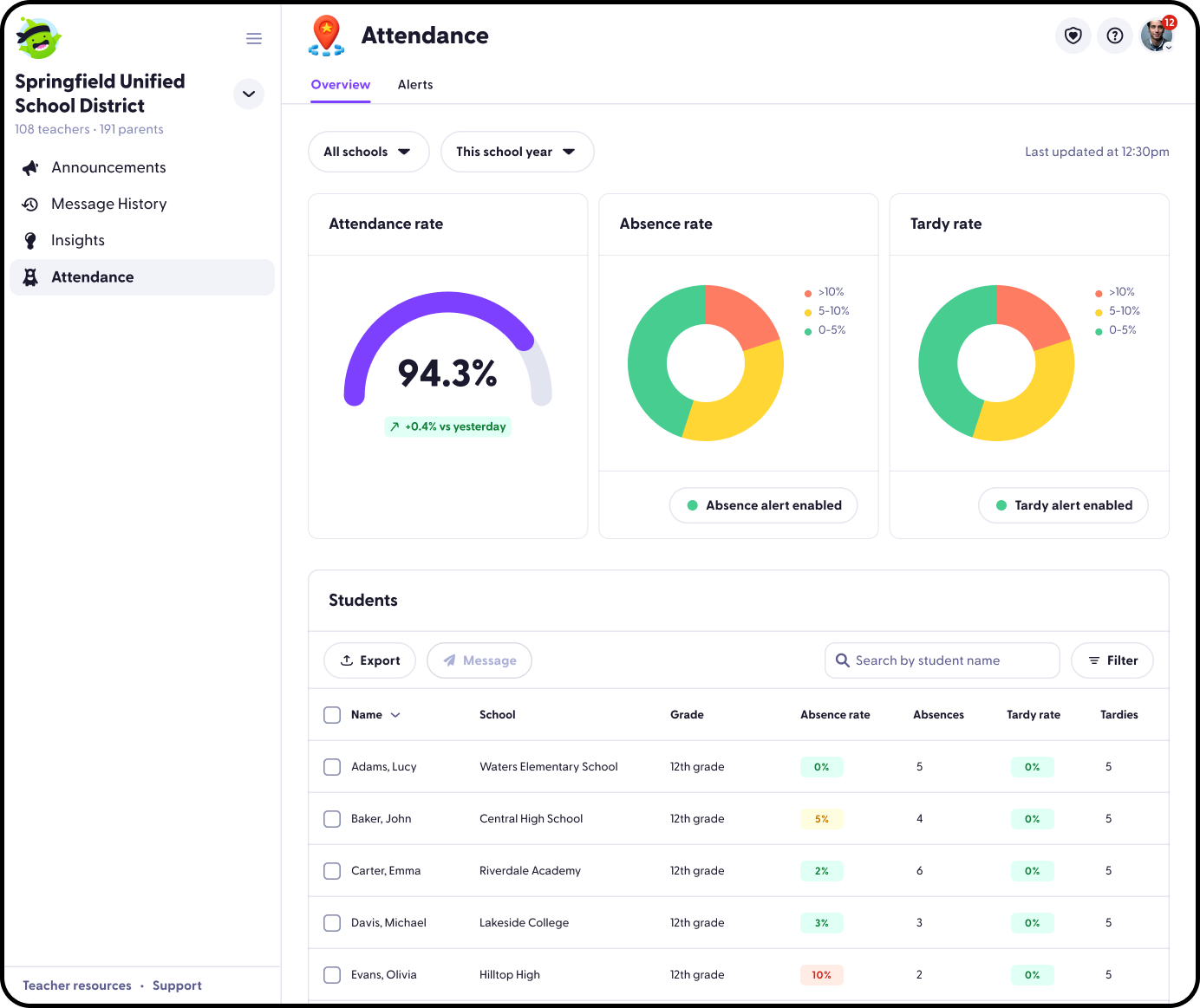
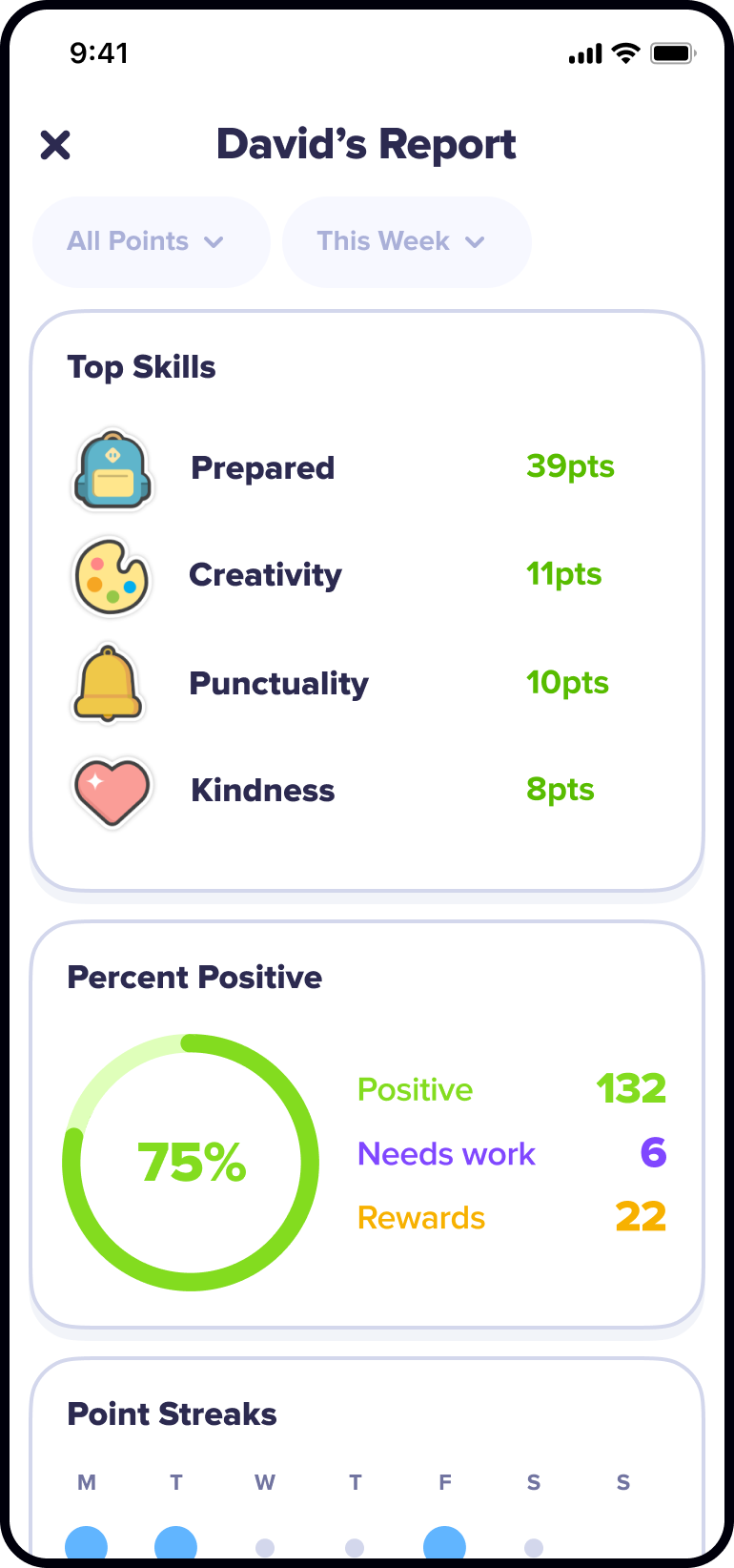
What I do
I help teams turn fuzzy product opportunities into shipped experiences. My work spans
product strategy, interaction design, visual systems, growth experiments, front-end
engineering, and the connective tissue between them.
How I use AI
I use AI as a creative and technical multiplier, not a replacement for taste. It
helps me explore more directions, move faster through production, document systems,
prototype ideas, and pressure-test decisions while keeping the final judgment human.
Reaching me
The best way to reach me is by email at
hey@banders.design. If you have a project in
mind, a little context up front helps me understand where I can be most useful.